Large Language Models: Die Bedeutung
Der Begriff Large Language Model beschreibt eine spezielle Art von künstlicher Intelligenz, die auf das Verarbeiten und Generieren von Sprache spezialisiert ist. Aber was ist ein LLM genau?
Ein Large Language Model ist ein Sprachmodell, das mithilfe von Deep Learning trainiert wurde, um menschliche Sprache zu verstehen und eigene Texte zu generieren. Dabei basiert es auf einer enormen Menge an Trainingsdaten, darunter Texte aus Büchern, Artikeln, Foren oder wissenschaftlichen Publikationen. Diese Modelle lernen nicht einfach auswendig, sondern berechnen auf Basis von Wahrscheinlichkeiten, welches Wort in einem Text als Nächstes kommen sollte. Kurz gesagt: Ein LLM ist ein KI-Sprachmodell, das Sprache statistisch vorhersagt und damit Antworten, Zusammenfassungen und Inhalte generieren kann.
Moderne Sprachmodelle wie ChatGPT basieren auf extrem großen Datenmengen und einer enormen Anzahl an Parametern, den lernbaren Einheiten innerhalb eines neuronalen Netzwerks. Diese Parameter sind vergleichbar mit den Synapsen im menschlichen Gehirn: Je mehr davon vorhanden sind, desto feiner kann das Modell Zusammenhänge erkennen, Sprache deuten und auf Anweisungen reagieren.
Während frühere Modelle mit einigen Millionen Parametern arbeiteten, kommen heutige Large Language Models auf mehrere Billionen. Diese enorme Komplexität ermöglicht es ihnen, sehr kontextbezogen, vielseitig und mit erstaunlicher Treffsicherheit auf Texteingaben zu reagieren.
So funktionieren LLMs
Ein Large Language Model ist kein statisches Nachschlagewerk, sondern ein lernendes System, das auf Grundlage von Wahrscheinlichkeiten arbeitet. Zentral für seine Leistung sind die Trainingsdaten, mit denen es „gefüttert“ wurde, sowie die Rechenressourcen, die beim Training zum Einsatz kommen.
Bevor ein LLM sinnvoll arbeiten kann, muss es trainiert werden und das geschieht auf der Grundlage riesiger Datensätze. Dazu gehören unter anderem Texte aus Büchern, wissenschaftlichen Publikationen, Online-Artikeln oder öffentlich zugänglichen Foren. Während des Trainings analysiert das Modell diese Inhalte und lernt, welche Wortfolgen, Formulierungen und Zusammenhänge typisch sind. Es merkt sich dabei nicht die Inhalte selbst, sondern die Wahrscheinlichkeiten, mit denen bestimmte Wörter oder Satzkonstruktionen auftreten.
Die Schnittstelle zwischen Mensch und LLM bilden KI-Chatbots wie ChatGPT, Google Gemini oder Google AIOs. Über einfache Texteingaben, sogenannte Prompts, stellen Nutzer Fragen, geben Anweisungen oder formulieren Aufgaben. Das LLM verarbeitet diese Eingaben, berechnet passende Antworten auf Basis erlernter Wahrscheinlichkeiten und gibt die Ergebnisse in natürlicher Sprache aus. So entsteht ein Dialog, der sich oft sehr menschlich anfühlt, obwohl im Hintergrund ein rechenintensiver Prozess abläuft, der auf Milliarden von Parametern basiert. Dieser Prozess macht das Modell extrem flexibel: Es kann auf individuelle Anweisungen reagieren, neue Themen erschließen und sich an verschiedene Aufgaben anpassen, von E-Mails über Produktbeschreibungen bis hin zu Codes oder komplexen Analysen.
Das Training eines leistungsfähigen Sprachmodells erfordert enorme Rechenleistung. Je größer der Datensatz und je mehr Parameter verarbeitet werden müssen, desto höher ist der Bedarf an Rechenressourcen. Auch bei der späteren Anwendung kommt es auf optimierte Prozesse an, um schnelle und relevante Ergebnisse zu liefern.
Einsatzmöglichkeiten von Large Language Models
Large Language Models sind längst keine Zukunftsvision mehr: Sie sind bereits aktiv im Einsatz, um digitale Arbeitsprozesse effizienter, flexibler und individueller zu gestalten. Vor allem im Marketing, in der Kommunikation und im Wissensmanagement bieten sie konkrete Vorteile. So unterstützen wir von seowerk dabei, LLMs für Ihr Unternehmen nutzbar zu machen:
Content-Generierung und Texterstellung
LLMs können Content wie Social-Media-Inhalte, SEO-Texte, Produktbeschreibungen oder interne Kommunikationsmittel in hoher Geschwindigkeit und Qualität erstellen. Dabei werden nicht nur Texte generiert, auch Strukturvorschläge, kreative Varianten oder stilistische Optimierungen sind möglich. Die automatisierte Texterstellung entlastet Teams, beschleunigt Prozesse und liefert skalierbaren Output: Das ist besonders im digitalen Marketing ein echter Vorteil. Wir unterstützen Sie dabei, Inhalte mithilfe von LLMs effizient zu erstellen und sorgen gleichzeitig dafür, dass die Modelle so angepasst und eingesetzt werden, beispielsweise mit der Nutzung individueller RAG-Systeme, dass der Content auch inhaltlich genau zu Ihren Unternehmenszielen passt.
LLMO
Immer mehr Menschen nutzen LLMs wie ChatGPT, Perplexity oder Claude als Suchmaschine. Genau hier setzt LLMO (Large Language Model Optimization) an: Eine neue Disziplin im klassischen SEO, bei der Inhalte so optimiert werden, dass sie in den Antworten von Sprachmodellen sichtbar werden. Für Unternehmen bedeutet dies, dass Sichtbarkeit in klassischen Suchmaschinen allein nicht mehr reicht. Wer heute Reichweite aufbauen will, muss verstehen, wie Language Models Informationen verarbeiten und entsprechend optimierte Inhalte bereitstellen. Wir helfen Ihnen dabei, Inhalte so aufzubereiten, dass sie von Large Language Models wie ChatGPT oder Google Gemini besser erkannt und verarbeitet werden und helfen dabei, Ihre Sichtbarkeit in KI-basierten Suchergebnissen gezielt zu steigern.
LLMs als RAG-Systeme
Mit Retrieval Augmented Generation (RAG) lassen sich LLMs um eigene Unternehmensdaten erweitern. Statt nur auf allgemeine Trainingsdaten zurückzugreifen, können beispielsweise interne Dokumente, Handbücher oder Wissensdatenbanken angebunden werden. So wird das Modell zur unternehmensspezifischen Antwortmaschine, ideal für konkrete Use Cases wie Onboardings, Support oder Wissensmanagement. Wir bei seowerk entwickeln individuelle RAG-Systeme, die Large Language Models gezielt mit unternehmensspezifischem Wissen verknüpfen. So entstehen KI-Lösungen, die nicht nur allgemeine Antworten liefern, sondern fundierte, kontextbezogene Informationen speziell für Ihre Anwendungsfälle.
LLMs als Chatbots
Moderne Chatbots basieren nicht mehr auf starren Entscheidungsbäumen, sondern auf Sprach-KIs, die flexibel auf Nutzerfragen reagieren. LLM-basierte Chatbots verstehen Kontexte, verarbeiten Anweisungen und liefern relevante Antworten, auf Wunsch in Echtzeit und rund um die Uhr, beispielsweise zur Unterstützung im Kundenservice oder als interne Helfer für Mitarbeitende. In Verbindung mit RAG-Architekturen lassen sich diese Systeme an individuelle Informationsquellen koppeln. Wir entwickeln KI-Chatbots auf Basis von Large Language Models, die in natürlicher Sprache kommunizieren und individuell auf Ihr Unternehmen zugeschnitten sind. Dabei sorgen wir dafür, dass der Chatbot nicht nur überzeugend antwortet, sondern auch auf relevante Inhalte aus Ihren eigenen Datenquellen zugreifen kann.
LLMs als KI Agents
Ein nächster Schritt in der Nutzung von Large Language Models sind KI Agents: Modelle, die nicht nur Antworten generieren, sondern ganze Aufgaben übernehmen. Sie agieren auf Basis klar definierter Workflows, interagieren mit Schnittstellen, recherchieren, fassen zusammen oder treffen Entscheidungen im Rahmen definierter Grenzen. Gerade in komplexen digitalen Arbeitsabläufen entstehen hier neue Formen der Automatisierung, bei denen LLMs aktiv mitdenken und handeln. Wir entwickeln KI Agents auf Basis von LLMs, die eigenständig Aufgaben übernehmen, Abläufe automatisieren und sich nahtlos in Ihre bestehenden Prozesse integrieren.
„*“ zeigt erforderliche Felder an
Vorteile & Herausforderungen von LLMs
Large Language Models sind leistungsstark, aber nicht fehlerfrei. Für Unternehmen ergeben sich durch den Einsatz sowohl klare Vorteile als auch relevante Herausforderungen, die bei der Planung und Implementierung berücksichtigt werden sollten.
Einer der größten Vorteile von LLMs liegt in der Skalierbarkeit: Aufgaben wie Texterstellung, Recherche, Datenzusammenfassung oder Standardkommunikation lassen sich automatisieren, ohne Einbußen bei der Qualität. Das bedeutet weniger Zeitaufwand für Routineaufgaben und mehr Raum für kreative und strategische Arbeit.
LLMs ermöglichen zudem völlig neue Formen der Informationsverarbeitung. In Verbindung mit RAG-Systemen oder als KI Agents können sie unternehmensspezifisches Wissen verfügbar machen, schnell auf Fragen reagieren oder ganze Abläufe unterstützen. Dadurch entstehen effizientere Workflows, die manuell nicht oder nur mit großem Aufwand realisierbar wären.
Darüber hinaus lassen sich LLMs flexibel anpassen, etwa durch Feintuning, Custom Prompts oder die Integration individueller Datensätze. Unternehmen erhalten damit Werkzeuge, die exakt auf ihre Anforderungen zugeschnitten sind.
Trotz aller Möglichkeiten sind LLMs kein Selbstläufer. Eine der größten Herausforderungen sind Halluzinationen: LLMs können Inhalte erfinden, die zwar sprachlich korrekt, aber faktisch falsch sind. Deshalb ist eine menschliche Kontrolle der generierten Ergebnisse essenziell, besonders bei sensiblen Themen oder rechtlich relevanten Inhalten.
Ein weiterer kritischer Punkt betrifft den Datenschutz. Werden sensible Informationen verarbeitet oder gespeichert, müssen DSGVO-Vorgaben und andere gesetzliche Anforderungen strikt eingehalten werden. Gerade bei extern gehosteten Systemen sollte genau geprüft werden, wo und wie die Daten verarbeitet werden.
Nicht zuletzt erfordern LLMs ein grundlegendes Verständnis ihrer Funktionsweise. Wer das Potenzial voll ausschöpfen möchte, sollte Zeit und Ressourcen in Strategie, Testing und Weiterentwicklung investieren.
Hier setzen wir bei seowerk an: Wir unterstützen Unternehmen dabei, LLMs sinnvoll, sicher und effizient einzusetzen, durch individuelle Beratung, durch die Entwicklung von RAG-Systemen, durch LLM-optimierte Inhalte, oder durch maßgeschneiderte KI-Workshops. Unsere Expertise hilft Ihnen dabei, Herausforderungen realistisch einzuschätzen und gezielt anzugehen, passende Lösungen zu identifizieren und das volle Potenzial von LLMs nutzbar zu machen.
Large Language Models richtig nutzen
LLMs sind mehr als ein Trend: Sie sind Werkzeuge, die Prozesse, Kommunikation und Inhalte in Unternehmen grundlegend verändern. Damit das gelingt, braucht es mehr als nur Zugang zu einem Modell wie ChatGPT oder Gemini. Entscheidend ist die Frage: Wie kann ein LLM konkret für mein Unternehmen arbeiten und welche Strukturen brauche ich dafür?
Wir begleiten Unternehmen genau bei dieser Frage. Als KI-Agentur mit Spezialisierung auf KI-Sprachmodelle und -Lösungen unterstützen wir dabei, die Potenziale von LLMs in konkrete Anwendungen zu übersetzen. Unsere Stärke liegt darin, AI-Technologie mit konkreten Business-Zielen zu verbinden. Wir machen LLMs für Marketingteams, IT-Abteilungen oder Geschäftsführungen verständlich und nutzbar.
Wenn Sie mehr darüber erfahren möchten, wie ein LLM in Ihrem Unternehmen sinnvoll eingesetzt werden kann, stehen wir Ihnen gerne zur Seite. Wir beraten, entwickeln und begleiten, mit Fokus auf Lösungen, die langfristig funktionieren. Außerdem helfen wir Ihnen auch mit anderen Online-Marketing Leistungen weiter.
Interne Links
- SEO Agentur: https://www.seowerk.de/seo-agentur/
- KI-Agentur: https://www.seowerk.de/ki-agentur/
- Google AI Overviews: https://www.seowerk.de/news/google-aio/
- Large Language Model Optimization: Zukunft der Suche?: https://www.seowerk.de/news/llmo/
- RAG-System: Wie Retrieval Augmented Generation Ihr Unternehmen mit erweiterter KI / AI unterstützt: https://www.seowerk.de/news/rag-system-wie-retrieval-augmented-generation-ihr-unternehmen-mit-erweiterter-ki-ai-unterstuetzt/
- Andere Leistungen: https://www.seowerk.de/leistungen/
Welches Potenzial bieten Large Language Model Optimization (LLMO), Generative AI Optimization (GAIO) oder Generative Engine Optimization (GEO)?
Die KI-Revolution wurde am 30.11.2022 durch die Veröffentlichung des populärsten KI-Chatbots „Chat-GPT“ weltweit eingeleitet, welcher auf dem Large Language Model (LLM) GPT des Unternehmens OpenAI basiert. Nach 2 Monaten gab es bereits 100 Millionen Nutzer, im Oktober 2023 zählte die Chat-GPT Website ca. 1,7 Milliarden Besucher. Auch in Deutschland ist das Tool bereits bis in den Mainstream vorgedrungen. Stand November 2023 haben bei einer Befragung von ca. 1000 Teilnehmern 80% angegeben, bereits von Chat-GPT gehört oder gelesen zu haben. 34% der Befragten haben den Chatbot bereits genutzt, 13% nutzen ihn sogar häufig.
Angesichts dieser Nutzerzahlen kommt bei Marketern & Unternehmen unweigerlich die Frage auf, ob man LLMs & KI-Chatbots gewinnbringend für die eigene Marketingstrategie nutzen kann. Ein erfolgreiches Beispiel dazu gibt es bereits. Das US-Unternehmen „Logikcull“ hat bei einer Umfrage unter Neukunden herausgefunden, dass ein Großteil der Erstkontakte über Chat-GPT zustande gekommen ist. Könnte man einen solchen Effekt replizieren, hätte man einen völlig neuen Kanal zur Kundenakquise gewonnen, welcher von hunderten Millionen potentiellen Kunden genutzt wird.
In der Welt der Suchmaschinenoptimierung gibt es bereits einige Wortschöpfungen, um diesen etwaigen Optimierungsprozess zu beschreiben: Large Language Model Optimization (LLMO), Generative AI Optimization (GAIO) oder Generative Engine Optimization (GEO). Manche Experten beschreiben sogar einen Paradigmenwechsel im Bereich der organischen Optimierung mit dem Begriff "Search Everywhere Optimization" (SEO). Im Folgenden geben wir einen allgemeinen Überblick zu LLMs und KI-Chatbots, deren Auswirkungen auf die bestehende Customer-Journey und erste, theoretische Optimierungsmaßnahmen.
Large Language Models: Definition und Funktionsweise
Large Language Models wie GPT (Generative Pre-trained Transformer) sind generative Sprachmodelle, die mit riesigen Datenmengen (Trainingsdaten) gefüttert wurden. Auf Basis dieser Trainingsdaten ist es LLMs bspw. möglich, Texte zu generieren, Fragen zu beantworten oder Texte zu übersetzen. Dabei ist es wichtig zu verstehen, dass mit „künstlicher Intelligenz“ in diesem Kontext keine wahre künstliche Intelligenz gemeint ist. Vielmehr handelt es sich bei der Architektur und Funktionsweise von LLMs um clevere Statistik: Auf Basis der Trainingsdaten wird den Modellen beigebracht, ob der gelieferte Output korrekt oder inkorrekt war. Sofern das gelieferte Ergebnis inkorrekt war, wird das Tool entsprechend neu kalibriert, bis die Anzahl der fehlerhaften Ergebnisse kaum wahrnehmbar ist. Der Output eines Tools basiert dabei auf Vorhersagen und Wahrscheinlichkeiten: Wort für Wort ermittelt das LLM die wahrscheinlichste Fortsetzung eines Textes.
Mit einem solchen LLM als Grundlage können nun KI-Chatbots erstellt werden. Unter einem KI-Chatbot wie Chat-GPT versteht man Chatbots, die auf LLMs zurückgreifen, um Nutzeranfragen zu verstehen, zu verarbeiten und zu beantworten. Handelsübliche Chatbots würden dabei auf vordefinierte Regeln anstatt ein LLM zurückgreifen, wodurch sie wesentlich beschränkter in ihrer Funktionsweise sind.

KI-Chatbots: Chat-GPT, Bing Chat und Co.
Mit LLMs und den darauf basierten KI-Chatbots hat man also mächtige Tools an der Hand. Anwendungsbereiche gibt es viele, darunter Coding, Texterstellung, Datenmanipulation, aber auch Unterstützung bei ganz alltäglichen Fragen. Weiterhin können bspw. Dateien oder Videos inhaltlich zusammengefasst und Bilder generiert werden. Und wer gerne seinen eigenen, persönlichen Assistent kreieren möchte, kann seinen eigenen GPT bauen und mit Daten füttern.
Diese große Bandbreite erklärt auch die enorme Popularität von Chat-GPT: Das Tool kann sowohl für geschäftliche als auch für private Zwecke verwendet werden. Zum Beispiel kann man sich in einem Chat-Fenster Interpretationen zu einem hochgeladenen Google Ads Reporting liefern lassen, während im nächsten Chat gerade ein Rezept für das Mittagessen generiert wird, welches genau die Zutaten benutzt, die man aktuell im Kühlschrank hat.
Eine der größeren Schwächen von KI-Chatbots ist dabei, dass die Trainingsdaten mit der Zeit veralten. Bei Chat-GPT 4 beispielsweise stammen die Trainingsdaten vom April 2023, was Entwicklungen ab diesem Zeitpunkt für das Tool quasi unsichtbar macht. Es gibt jedoch auch dafür einen Workaround in Form einer Anbindung an den ultimativen, dynamischen Datensatz in Form vom Suchmaschinen-Index. Sofern ein KI-Chatbot in der Lage ist, auf Suchergebnisse, bspw. von Google oder Bing, zuzugreifen, können auch Anfragen bearbeitet werden, welchen top-aktuelle Trainingsdaten zugrunde liegen.
KI-Chatbots und Suchmaschinen
Eine solche Funktion wird zwar schon über Chat-GPT 4 abgedeckt, wo es seit Sommer 2023 ein Feature namens „Browse with Bing“ gibt. Eine wirkliche Symbiose aus KI-Chatbot und Suchmaschinen-Index hat man hiermit allerdings nicht. Diese Rolle nehmen aktuell eher Services wie Bing-Chat, Google Gemini (ehemals Bard) oder You Chat ein.
Neben einem Fix für das Problem der alternden Trainingsdaten versprechen sich Google und Microsoft mit Hilfe dieser Tools weiterhin einen Paradigmenwechsel in der Welt der traditionellen Suchmaschinen. So fortschrittlich wie die heutigen Suchmaschinen-Algorithmen auch sind, ein KI-Chatbot wird früher oder später besser in der Lage sein, die Nutzerintention zu erkennen und zu befriedigen. So ist es für Tools wie Chat-GPT bspw. möglich, wesentlich besser auf komplexe Querys einzugehen und flexiblere Antworten auszuspielen.
Ein Versuch, Suchmaschine und KI-Chatbot miteinander zu verbinden, wird von Google gerade entwickelt. Mithilfe der Search Generative Experience (SGE) soll für einen Großteil der Queries in der normalen Google Suche ein Snapshot auf Basis eines KI-Chatbots ausgespielt werden. Das Tool befindet sich aktuell noch in der Testphase. Laut aktuellem Stand könnte es je nach Nische zukünftig für einen großen Teil der Suchanfragen einen solchen SGE-Snapshot geben. Wie stark sich die traditionelle Suche dadurch ändern wird, hängt wohl von den relevanten Nutzerkennzahlen bei der Interaktion mit dem Tool ab. Fest steht aber: Die KI-Revolution wird sich mit hoher Wahrscheinlichkeit auch auf die großen Suchmaschinen auswirken und die gewohnte Customer Journey ändern. Wann das Rollout von SGE erfolgt, wie das Tool von Nutzern angenommen wird und wie einschneidend sich Klickrate und Nutzerverhalten auf dieser Basis ändern werden, steht allerdings noch in den Sternen.

LLMO, GAIO & GEO: Traffic über KI-Chatbots erhalten
Nachdem nun die aktuelle Situation bzgl. LLMs, KI-Chatbots und deren (möglichen) Auswirkungen auf Suchmaschinen erläutert wurden, bleibt die Frage: Wie kann ich mich als Unternehmen auf diese Änderungen einstellen?
Vorab: Wie auch bei Suchmaschinen gibt es für Large Language Model Optimisation (LLMO) (oder Generative AI Optimization (GAIO) bzw. Generative Engine Optimization (GEO)) keine Schritt-für-Schritt-Anleitung der Hersteller. Eine Ableitung von gewinnbringenden Maßnahmen basiert auf Trial-and-Error, was ein langwieriger Prozess ist. Von daher gibt es aktuell eher theoretische Ansatzpunkte und keine langfristigen Erfahrungswerte mit Ursache & Wirkung. Weiterhin können sich etwaige Maßnahmen und Erträge je nach Branche und Nische massiv unterscheiden.
1. Erzeugen von Kookkurrenzen
Da der Output von KI-Chatbots wie Chat-GPT auf Trainingsdaten basiert, kann eine Nennung der eigenen Marke oder des Produkts nur erfolgen, wenn man in den Trainingsdaten im korrekten Kontext auftaucht. Dabei können mit Trainingsdaten je nach Datenquelle handelsübliche Datensätze oder Suchmaschinen gemeint sein. Als Beispiel dazu: Wenn ein potentieller Kunde bei Chat-GPT nach einer Pfanne für unter 80€ sucht, die zum Braten von Hähnchenfleisch geeignet und leicht zu reinigen ist, muss mein Produkt im Kontext dieser Query in den Trainingsdaten auftauchen. Vorzugsweise in mehreren Quellen. Diese Art der “Streuung” von Inhalten bezeichnet man als “Kookkurrenzen”. Zum Erzeugen von Kookkurrenzen bleiben primär klassische PR-Arbeit und eine langfristige Content-Strategie. Je höher die Markenbekanntheit, Content-Qualität und Content-Quantität, desto höher die Chance, extern referenziert zu werden.
2. EEAT (Expertise, Experience, Authoritativeness, Trustworthiness)
Unter EEAT versteht man eine der relevantesten Richtlinien für Googles menschliche, interne Evaluatoren der Qualität der Suchergebnisse. Quelle und Inhalt sollen in diesem Kontext auf die empfundene Expertise, Erfahrung, Autoritätsempfinden und Vertrauenswürdigkeit geprüft werden. EEAT an sich ist kein direkter Rankingfaktor, sondern eher ein Qualitätsmerkmal von Content und Publishern. Bei der Evaluierung von EEAT können sowohl OffPage-Faktoren, wie die bereits genannten "Kookkurrenzen", als auch OnPage-Faktoren, wie frei zugängliche Informationen zum Publisher (Impressum), herangezogen werden.
Faktoren, die EEAT begünstigen:- Sichtbares Verlinken von Autoren der Inhalte
- Gesamtqualität der Inhalte (Helpful Content)
- Topical Authority zum Thema
- Kookkurrenzen / Zitate von Inhalten auf anderen Portalen
- Aktualität der Inhalte
- etc.
3. Entität-basierte Content Strategie
Der gängige Ansatz in der Suchmaschinenoptimierung, pro Seite ein Keyword abzudecken, wird mit der KI-Revolution nicht mehr ausreichen. Stattdessen sollte der Fokus bei der Content-Strategie auf dem Bespielen von ganzen Entitäten liegen. Im engsten Sinne ist damit gemeint, dass weniger einzelne Begriffe für die Einordnung der Seite vom LLM genutzt werden, sondern wie tiefgreifend eine Seite sich mit der entsprechenden Entität im Kontext des Keywords auseinandersetzt. Hiermit qualifiziert man sich auch für die immer breiter angelegten Queries/Prompts, mit welchen in KI-Chatbots gearbeitet wird. Entsprechend gilt es zukünftig, Inhalte holistischer darzustellen und Entitäten ganzheitlicher zu recherchieren.
4. Allgemeine SEO-Faktoren
Neben den ausgefeilteren Punkten sollten auch die Basics nicht außen vor bleiben. Pagespeed bzw. Core Web Vitals, strukturierte Daten und eine optimierte UX werden auch für KI-Chatbots essenzielle Faktoren bleiben, insbesondere bei solchen, die direkt in Suchmaschinen integriert sind. Besonderes Augenmerk liegt dabei aktuell auf dem Punkt Crawlability, da einige große Publisher sich dazu entschlossen haben, OpenAIs GPT-Bot für das Crawling zu sperren. Hier am Beispiel der robots.txt der New York Times:
User-agent: GPTBot
Disallow: /Sofern Inhalte nicht gecrawlt werden können, ist es natürlich auch nicht möglich, mit Website-Ergebnissen in den Tools aufzutauchen. Je nach Publisher ist es also essenziell, vor anderen Optimierungsstrategien erst abzuklären, ob das Auftauchen in LLMs überhaupt möglich sein soll.
5. Laufende Konkurrenzanalyse
Die Analyse von aktuellen Snapshots in Chat-GPT, Bing-Chat oder SGE (falls via VPN ein Zugriff besteht) sollte in den meisten Fällen recht aufschlussreich sein. Das Rad sollte man dabei nicht neu erfinden und möglichst versuchen, die beeinflussbaren On-Page Faktoren der Konkurrenten ähnlich umzusetzen. Im Optimalfall bemerkt man bei einer solchen Recherche, dass für gewisse Queries ganz andere Anforderungen an die Website gerichtet sind, als man mit dem eigenen Angebot momentan abbildet. In diesem Fall sollte man die eigene Seite bzgl. Inhalt, Suchintention etc. entsprechend anpassen.

Fazit
Zusammengefasst lässt sich sagen, dass das Thema LLMO (GAIO, GEO) hoch spannend ist. Je nach Ausprägung von Features wie Googles SGE könnten KI-Chatbots das Suchverhalten und die Customer Journey von Nutzern nachhaltig verändern. Für Anbieter von Waren und Dienstleistungen ist es daher essenziell, sich so früh wie möglich auf diesen Paradigmenwechsel einzustellen. Erster Schritt dabei wäre natürlich, weiterhin saubere SEO-Arbeit zu betreiben, da das Verhältnis zwischen SEO und LLM-basierten KI-Chatbots wie Chat-GPT und SGE relativ konsistent bleibt.
Inwiefern LLMs und deren Trainingsdaten für umkämpfte Bereiche wirklich beeinflusst werden können, bleibt fraglich. Der Umfang der Trainingsdaten ist teilweise so groß, dass zum Erzeugen von ausreichend Kookkurrenzen hunderte bis tausende externe Nennungen stattfinden müssten, welche dann noch zusätzlich in den Trainingsdaten auftauchen. Für mittelständische Unternehmen wäre dieses Vorhaben realistisch nicht umzusetzen. Je nischiger ein Thema allerdings ist, desto besser stehen die Chancen, auf Basis einer langfristig angelegten Content-Strategie den Weg in KI-generierte Snapshots zu finden.
Quellen
- https://www.techopedia.com/de/30-statistiken-zu-chatgpt-trends-anwendung-und-prognosen
- https://de.statista.com/statistik/daten/studie/1453047/umfrage/bekanntheit-von-ki-einsatz-zur-textgenerierung/
- https://www.bigdata-insider.de/was-ist-ein-large-language-model-a-d735d93bbc24d3c4091de8ce25aa36e8/
- https://www.techopedia.com/de/definition/large-language-model-llm
- https://www.moin.ai/chatbot-lexikon/regelbasierte-chatbots
- https://www.cm.com/de-de/blog/chatgpt-llms-potenzial/
- https://www.analyticaa.com/generative-ai-optimization-gaio-large-language-model-optimization-llmo/
- https://www.derinformatikstudent.de/openai-update-gpt-4-turbo-chatgpt/
- https://blog.google/products/search/generative-ai-search/
- https://peakace.agency/de/latest/sge-rollout-spekulationen/
- https://developers.google.com/search/blog/2022/12/google-raters-guidelines-e-e-a-t?hl=de
- https://www.seokratie.de/google-sge/
- https://www.sem-deutschland.de/seo-glossar/e-a-t-und-ymyl/
- https://www.sem-deutschland.de/blog/llmo-oder-gaio/
- https://www.searchenginejournal.com/googles-gemini-impact-on-seo/506610/
- https://omr.com/de/daily/gaio-llmo-geo-aio-marketing
- https://www.linkedin.com/pulse/ultimate-guide-llmo-geo-aio-malte-landwehr-khqne/
I. Die Wiege der Intelligenz: Antike und Mittelalterliche Vorläufer
Die Vorstellung von künstlichem Leben und intelligenten Maschinen ist so alt wie die Menschheit selbst. Schon in der Antike und im Mittelalter finden sich Spuren dieser Faszination, die den geistigen Grundstein für die spätere Entwicklung der Künstlichen Intelligenz legten.
Philosophische Konzepte künstlichen Lebens
Bereits in der Antike dachten Philosophen intensiv über Maschinen nach, die ohne menschliche Unterstützung arbeiten könnten.3 Aristoteles (384-322 v. Chr.) legte mit seinen Überlegungen zu automatisierten Mechanismen einen entscheidenden geistigen Grundstein für heutige KI-Konzepte.3 In seinem Werk „Politik“ schrieb er, dass, wenn jedes Werkzeug das ihm zukommende Werk von selbst verrichten könnte, weder der Werkmeister Gehilfen noch die Herren Sklaven bräuchten.3 Diese frühe Reflexion über die Automatisierung von Arbeit deutet auf eine grundlegende Frage nach der Natur der Arbeit und der Rolle des Menschen hin.
Die Faszination für künstliches Leben zeigte sich auch in der Idee des Homunculus, dem lateinischen Begriff für „kleiner Mensch“, der im Spätmittelalter in alchemistischen Kontexten entwickelt wurde.5 Goethe verhalf der Homunkulus-Idee in seinem „Faust II“ zu allgemeiner Bekanntheit.6 Parallel dazu experimentierte Jābir ibn Hayyān in der islamischen Alchemie (Takwin) mit künstlichem Leben aus dem Labor.6 Ein weiteres berühmtes Beispiel ist der Golem aus der jüdischen Folklore des 16. Jahrhunderts, ein aus Lehm geschaffenes Wesen, das durch Magie zum Leben erweckt wurde, um Menschen bei der Arbeit zu helfen und sie zu schützen.6 Diese Konzepte, obwohl fantastisch und im Reich der Alchemie und Philosophie verbleibend 7, waren frühe Versuche, die Grenzen menschlicher Fähigkeiten und die Natur der Intelligenz zu ergründen. Sie repräsentierten die frühesten Bestrebungen der Menschheit, künstliche Handlungsmacht und simulierte Intelligenz zu konzeptualisieren. Diese tief verwurzelte intellektuelle Neugier auf die Frage, was „Leben“ oder „Denken“ ausmacht und ob es konstruiert oder herbeigeführt werden kann, bereitete den Boden für spätere wissenschaftliche Untersuchungen.
Frühe Automaten und mechanische Wunderwerke
Die Antike war Zeuge der Entstehung erstaunlicher mechanischer Automaten, die oft von mythologischen Erzählungen inspiriert waren oder praktischen Zwecken dienten. So schrieb man Hephaestus, dem griechischen Gott des Feuers und Schmiedens, die Schaffung allerlei nützlicher Automaten zu.6 Eine andere Legende besagt, dass Pygmalion, ein zypriotischer Künstler, eine so kunstvoll geschnitzte Elfenbeinstatue schuf, dass er sich in sie verliebte und sie zum Leben erwachte.6
Der griechische Erfinder Ktesibios aus dem 3. Jahrhundert v. Chr. baute eine Reihe erstaunlicher Automaten, darunter eine präzise Wasseruhr, deren Genauigkeit 2000 Jahre lang unübertroffen blieb, und eine „programmierbare“ Wasserorgel.6 Philon von Byzanz, ein Schüler Ktesibios', verfasste wichtige Werke über Pneumatik und Mechanik, die Anleitungen zum Bau von Automaten enthielten, wie das „Staton – ein automatisches Theater“ und eine „Automatische Dienerin“, die Wein in ein Glas einschenkte, sobald es auf ihre Handfläche gestellt wurde.6 Einige von Philons Erfindungen können als früheste beschriebene Roboter angesehen werden.6
Ein bemerkenswertes Artefakt aus dieser Zeit ist der Antikythera-Mechanismus, der um 100 v. Chr. in Griechenland entwickelt wurde.4 Dieser komplexe mechanische Kalender mit Bronzezahnrädern gilt als erster analoger Computer und war in der Lage, astronomische Positionen und Sonnenfinsternisse vorherzusagen.4 Es gibt sogar Hinweise darauf, dass dieses raffinierte Werkzeug damals schon in kleiner Serie produziert wurde.6
Im Mittelalter, insbesondere im Orient, blühte der Automatenbau weiter auf. Al-Dschazari (12. Jh.) schuf komplexe Automaten wie die Elefantenuhr.3 Arabisches Wissen über Mechanik und Automatenbau gelangte im 9. Jahrhundert als Geschenke an europäische Höfe, wie eine Wasseruhr für Karl den Großen.9 Obwohl europäische Gelehrte von diesen fremdartigen Automaten fasziniert waren, fehlte es ihnen oft an mechanischem Wissen, und Automaten wurden im Hochmittelalter noch häufig als magische Gegenstände wahrgenommen.9 Erst ab dem 12. Jahrhundert wuchs das Wissen um Mechanik auch in Europa, und Automaten wurden zunehmend als mechanische Maschinen verstanden.9 Villard de Honnecourt (Mitte 13. Jh.) schuf erste historisch belegbare Automaten in Westeuropa, darunter einen Vogel, der Flüssigkeit aus einem Becher trank und gluckernde Trinklaute machte.9
Die Entwicklung von Automaten in der Antike und im Mittelalter war nicht nur ein Beweis für mechanisches Geschick, sondern auch ein Ausdruck des Wunsches, die Natur zu beherrschen und übernatürliche Kräfte zu imitieren oder zu demonstrieren. Über die reine Nützlichkeit hinaus dienten diese Maschinen oft dazu, zu verblüffen, zu beeindrucken oder den Glauben an höhere Mächte oder die Genialität ihrer Schöpfer zu stärken.8 Dies deutet auf eine frühe Verbindung zwischen der wahrgenommenen „Intelligenz“ oder „Autonomie“ von Maschinen und ihrer Fähigkeit hin, die menschliche Wahrnehmung zu beeinflussen – ein Thema, das in späteren KI-Diskussionen immer wieder auftauchen sollte.
II. Die Geburt des Denkens in Maschinen: Von der Logik zur Rechenmaschine
Die Neuzeit markierte einen entscheidenden Übergang von der bloßen mechanischen Nachahmung zur systematischen Erforschung der Logik und der Informationsverarbeitung, die für die Entwicklung der Künstlichen Intelligenz unerlässlich sind.
Philosophische Grundlagen der Neuzeit
Im 17. Jahrhundert spekulierte der Mathematiker und Philosoph Gottfried Wilhelm Leibniz, dass menschliches Denken auf reine mechanische Berechnung reduzierbar sei – eine gewagte These für seine Zeit.6 Er entwickelte die Idee des Rechnens im Binärsystem 10 und die Vorstellung einer binär arbeitenden Maschine im Jahr 1679, setzte diese jedoch nicht in die Tat um.10 Seine Überlegungen legten jedoch ein wichtiges Fundament für die aufkommende Philosophie der künstlichen Intelligenz des 20. Jahrhunderts.6
René Descartes (1596–1650) prägte mit seinem grundlegenden Werk Discours de la méthode (1637) das Konzept der „bête machine“, wonach Tiere hochkomplexe Maschinen oder Automaten seien, die von Gott geschaffen wurden.11 Er glaubte, dass es für Menschen plausibel wäre, eines Tages tierähnliche Maschinen zu konstruieren, die sich wie echte Tiere verhalten könnten.11 Im Gegensatz zu Descartes' eher theoretischem Ansatz setzte der deutsche Jesuit Athanasius Kircher (1602–1680) diese Ideen praktisch um. Kircher baute einen sprechenden Kopf, singende Vögel und Figuren, die Musikinstrumente spielten.11
Georg Boole, ein mathematischer Autodidakt und Logiker, schuf 1854 mit seinem Werk „The Laws of Thought“ die Boolesche Algebra.6 Dies war ein entscheidender Grundstein im Fundament des Informationszeitalters, da sie die logischen Operationen formalisierte, die später die Basis für Computerprogramme bilden sollten.6 Die Idee, die einfachsten Theorien zu bevorzugen, oft William von Ockham (1285-1347) zugeschrieben und bekannt als Ockhams Rasiermesser, bildet im Kontext des maschinellen Lernens die konzeptionelle Grundlage für Techniken wie Regularisierung.4 Diese philosophischen und mathematischen Entwicklungen stellten die Weichen für die Vorstellung, dass Intelligenz durch formale Systeme und Berechnungen nachgebildet werden könnte.
Mechanische Rechenmaschinen als frühe KI-Vorläufer
Das 17. Jahrhundert war geprägt von einer starken Tendenz in den Naturwissenschaften und der Wirtschaft, die Welt in Zahlen zu erfassen, was zu einem sprunghaften Anstieg der durchzuführenden Rechenoperationen führte.12 Wilhelm Schickard (1592-1635) gilt als Erfinder der weltweit ersten mechanischen Rechenmaschine um 1624. Sein Gerät, überwiegend aus Holz und Metall gebaut, war für die vier Grundrechenarten ausgelegt und verfügte über eine Zehnerübertragung, was es als echte Rechenmaschine qualifizierte.12
Der Franzose Blaise Pascal (1623-1662) entwickelte 1644 die „Pascaline“ für Addition und Subtraktion, die in der Wissenschaft Anerkennung fand.10 Im 18. Jahrhundert folgten zahlreiche weitere funktionstüchtige Rechenmaschinen von Erfindern wie Anton Braun d. J., Philipp Matthäus Hahn und J. H. Müller.10 In dieser Zeit wurden auch Elemente der späteren programmgesteuerten Rechentechnik entwickelt, wie Lochstreifen- und Stiftwalzensteuerungen für komplizierte Abläufe in der Textilherstellung (z.B. der Jacquard-Webstuhl) und in Musik- und Unterhaltungsautomaten.10
Ein Meilenstein in der Entwicklung hin zu modernen Computern war Charles Babbage (1791-1871). Er konzipierte 1822 die Differenzmaschine zur Berechnung von Logarithmentabellen und 1834 die Analytical Engine, einen universellen mechanischen Digitalcomputer, der Anweisungen verarbeiten sollte.4 Obwohl diese Maschinen zu seinen Lebzeiten aufgrund fehlender finanzieller Mittel nie vollständig gebaut wurden 4, legten seine Konzepte wichtige Grundlagen für spätere Computerdesigns.4 Ada Lovelace (1815-1852), die eng mit Babbage zusammenarbeitete, gilt als die erste Programmiererin der Geschichte, da sie Algorithmen für Babbages Analytical Engine entwickelte.4
Im 19. Jahrhundert begann die industrielle Großproduktion mechanischer Rechenmaschinen, beispielsweise durch William Seward Burroughs, der 1888 die „American Arithmometer Company“ gründete, die später zur „Burroughs Adding Machine Company“ und zum weltweit größten Hersteller von schreibenden Addiermaschinen wurde.12 Hermann Hollerith entwickelte 1882 eine Tabellier- und Sortiermaschine für Lochkarten, die erfolgreich bei der 11. US-amerikanischen Volkszählung 1890 eingesetzt wurde und zur Gründung der Tabulating Machine Company führte, aus der 1924 die Firma IBM hervorging.10
Die Entwicklung mechanischer Rechenmaschinen und mathematischer Logik im 17. bis 19. Jahrhundert war der entscheidende Schritt von der bloßen Automatisierung physischer Bewegungen zu den Grundlagen der Informationsverarbeitung, die für die Künstliche Intelligenz unerlässlich sind. Die Abfolge von Leibniz' Ideen zum Binärsystem 10, Booles Algebra 6 und den mechanischen Rechnern von Schickard, Pascal und Babbage 4 zeigt einen klaren Wandel. Maschinen, die zuvor primär physische Aktionen ausführten, entwickelten sich zu Systemen, die abstrakte Informationen verarbeiten konnten. Leibniz' Vorstellung, Denken auf Berechnung zu reduzieren 6, und Booles Logik lieferten den theoretischen Rahmen dafür, wie Intelligenz formalisiert und berechnet werden könnte, während Babbage und Lovelace die architektonische Blaupause für programmierbare, universelle Berechnungen bereitstellten.4 Dies stellt eine kritische kausale Verbindung zwischen abstraktem Denken und praktischem Maschinendesign dar, die den Weg zur Idee „denkender Maschinen“ ebnete.
III. Die Ära der Pioniere: Die offizielle Geburtsstunde der KI
Das 20. Jahrhundert brachte mit Alan Turing und der Dartmouth Conference die entscheidenden Impulse, die die Künstliche Intelligenz als eigenständiges Forschungsfeld etablierten und ihren Namen prägten.
Alan Turing und der Turing-Test
Der britische Mathematiker Alan Turing entwickelte 1936 die Turing-Maschine, eine theoretische Rechenmaschine, die beweisen konnte, dass Maschinen kognitive Prozesse ausführen können, vorausgesetzt, diese Prozesse lassen sich in algorithmische Schritte zerlegen.4 Diese bahnbrechende Entdeckung legte einen fundamentalen Grundstein für die gesamte KI-Entwicklung.4
In seinem wegweisenden Artikel „Computing Machinery and Intelligence“ aus dem Jahr 1950 stellte Turing die tiefgreifende Frage, ob Maschinen Intelligenz besitzen könnten, und schlug den heute berühmten Turing-Test vor.4 Bei diesem Test soll ein menschlicher Richter in einem schriftlichen Frage-Antwort-Spiel nicht zuverlässig unterscheiden können, ob er mit einem Menschen oder einer Maschine kommuniziert.14 Der Test wurde zu einem pragmatischen Maßstab für maschinelle Intelligenz, der sich auf beobachtbares Verhalten konzentriert, anstatt eine exakte Definition von Intelligenz oder Bewusstsein zu liefern.15 Er zwang die Forscher, sich auf die Simulation menschlichen Denkens zu konzentrieren, was die Entwicklung von Sprachverarbeitung und Problemlösungsfähigkeiten in den Vordergrund rückte.15
Die Dartmouth Conference 1956: Prägung des Begriffs "Künstliche Intelligenz"
Die offizielle Geburtsstunde der Künstlichen Intelligenz wird häufig auf den 13. Juli 1956 datiert.14 Im Sommer 1956 trafen sich Computerwissenschaftler auf einer wegweisenden Konferenz am Dartmouth College in New Hampshire.4
Organisiert von John McCarthy (damals Assistenzprofessor für Mathematik in Dartmouth), Marvin Minsky, Nathaniel Rochester und Claude Shannon, war das „Dartmouth Summer Research Project on Artificial Intelligence“ ein grundlegendes Ereignis für das Feld.18 John McCarthy schlug hierfür schließlich den Begriff „Künstliche Intelligenz“ vor, um ein neutrales Forschungsfeld zu definieren, das sich von engeren Automaten- oder Kybernetik-Theorien abgrenzte.14
Das Hauptziel der Konferenz war es, den Stand der Forschung über intelligente Maschinen darzustellen und die Hypothese zu verfolgen, dass „jeder Aspekt des Lernens oder jedes andere Merkmal der Intelligenz im Prinzip so präzise beschrieben werden kann, dass eine Maschine ihn simulieren kann“.18 Die Teilnehmer kamen zu dem Ergebnis, dass Maschinen lernen und menschliche Intelligenz simulieren können.14 Die Dartmouth Conference war nicht nur eine Namensgebung, sondern ein Gründungsakt, der die KI von isolierten Experimenten zu einem kohärenten Forschungsfeld mit expliziten Zielen und einer gemeinsamen Vision transformierte. Die explizite Annahme, dass Intelligenz prinzipiell algorithmisch beschrieben und simuliert werden kann 18, lieferte eine klare und ehrgeizige Forschungsagenda. Dieses kollektive intellektuelle Engagement und die formale Benennung waren entscheidend, um Finanzierung und Talente anzuziehen und KI als legitimen Bereich der wissenschaftlichen Forschung zu etablieren, was den Grundstein für den folgenden Aufschwung legte.
Erste KI-Programme und Konzepte
Zeitgleich mit der Dartmouth Conference entwickelten Allen Newell und Herbert A. Simon das Programm „Logic Theorist“, das als das erste echte KI-Programm der Welt in die Geschichte einging.3 Dieses Programm konnte mathematische Theoreme beweisen und zeigte das Potenzial von symbolischer KI.
1958 entwickelte der amerikanische Psychologe Frank Rosenblatt das Perzeptron, das erste lernfähige künstliche Neuron.2 Dabei handelte es sich um ein mathematisches Modell eines künstlichen neuronalen Netzes, das als Grundlage für maschinelles Lernen diente.2 Obwohl Marvin Minsky durch eine Buchveröffentlichung die vielversprechende Idee des Perzeptron seines Schülers Frank Rosenblatt nachhaltig in der Öffentlichkeit diskreditierte und die Anfänge des Konnektivismus auf Eis legte 6, war es ein wichtiger Schritt in der Entwicklung lernfähiger Systeme.
1966 erschuf der deutsch-amerikanische Informatiker Joseph Weizenbaum das Computerprogramm „ELIZA“, den ersten Chatbot.14 ELIZA simulierte über Skripte eine Kommunikation mit Menschen, insbesondere einen Psychotherapeuten.14 Weizenbaum war überrascht und schockiert, dass einige Nutzer, einschließlich seiner Sekretärin, dem Programm menschliche Gefühle zuschrieben – ein Phänomen, das als „Eliza-Effekt“ bekannt wurde.20 ELIZA war eines der ersten Programme, das in der Lage war, den Turing-Test zu versuchen.20
Die folgende Tabelle gibt einen Überblick über die wichtigsten Meilensteine dieser Gründungsphase der KI:
| Jahr | Ereignis/Entwicklung | Schlüsselpersonen/Institutionen | Bedeutung für die KI |
| 1936 | Turing-Maschine | Alan Turing | Theoretischer Grundstein für die Berechenbarkeit kognitiver Prozesse 4 |
| 1950 | Turing-Test | Alan Turing | Pragmatischer Maßstab für maschinelle Intelligenz basierend auf menschlicher Interaktion 14 |
| 1956 | Dartmouth Conference | John McCarthy, Marvin Minsky, Nathaniel Rochester, Claude Shannon | Offizielle Geburtsstunde und Prägung des Begriffs "Künstliche Intelligenz" 14 |
| 1956 | Logic Theorist | Allen Newell, Herbert A. Simon | Erstes echtes KI-Programm, das mathematische Theoreme beweisen konnte 3 |
| 1958 | Perzeptron | Frank Rosenblatt | Erstes lernfähiges künstliches Neuron, Grundlage des Maschinellen Lernens 2 |
| 1966 | ELIZA | Joseph Weizenbaum | Erster Chatbot, simulierte menschliche Kommunikation 14 |
Diese Tabelle fasst die komplexen Informationen über die frühen KI-Meilensteine prägnant zusammen und macht sie visuell leicht verständlich. Sie ermöglicht es, die entscheidenden Schritte von der theoretischen Fundierung bis zu den ersten praktischen Anwendungen der KI schnell zu erfassen. Durch die Gegenüberstellung von Ereignissen, Personen und ihrer Bedeutung wird die kausale Beziehung zwischen visionären Ideen und den daraus resultierenden technologischen Fortschritten deutlich. Dies hilft, die historische Entwicklung der KI in übersichtlicher Form darzustellen.
IV. Höhen und Tiefen: Die KI-Winter und ihre Lehren
Nach einer Phase des anfänglichen Optimismus erlebte die KI-Forschung wiederholt Perioden der Ernüchterung und des Rückgangs, die als „KI-Winter“ bekannt wurden. Diese Phasen waren jedoch nicht nur Rückschläge, sondern auch kritische Lernphasen, die die Forschung dazu zwangen, ihre Ansätze zu überdenken und realistischere Ziele zu setzen.
Der erste KI-Winter (ca. 1974-1980)
Nach der anfänglichen Euphorie stieß die KI-Forschung auf erhebliche Herausforderungen, insbesondere in Bezug auf die Verarbeitungskapazität und die Speicheranforderungen der damaligen Computertechnologie.17 Die hochgesteckten Erwartungen an die Fähigkeiten von KI-Systemen konnten nicht erfüllt werden.23 Herbert Simon hatte 1957 optimistische Vorhersagen gemacht, dass Computer innerhalb von 10 Jahren Schachmeister werden und bedeutende mathematische Theoreme beweisen könnten. Obwohl diese Vorhersagen schließlich eintrafen (Deep Blue im Schach 1996, Vier-Farben-Theorem 2005), dauerte es viel länger als erwartet – 40 Jahre statt 10.26 Diese überzogene Zuversicht rührte von der vielversprechenden Leistung früher KI-Systeme bei einfachen Beispielen her, doch diese Systeme versagten „kläglich, wenn sie auf breitere oder schwierigere Probleme angewendet wurden“.26
Ein Hauptgrund für die Ernüchterung war, dass die meisten frühen Programme nur einfache syntaktische Manipulationen durchführten und kein echtes Verständnis für ihr jeweiliges Thema hatten.26 Dies zeigte sich besonders bei den frühen maschinellen Übersetzungsversuchen, die trotz großzügiger Finanzierung durch den US National Research Council nach dem Sputnik-Start 1957 scheiterten. Man nahm an, dass einfache grammatikalische Regeln und elektronische Wörterbücher für eine genaue Übersetzung russischer wissenschaftlicher Arbeiten ausreichen würden. Es wurde jedoch deutlich, dass „genaue Übersetzung Hintergrundwissen zur Auflösung von Mehrdeutigkeiten und zur Feststellung des Satzinhalts erfordert“.26
Der ALPAC-Report (Automatic Language Processing Advisory Committee) von 1966 kritisierte die maschinelle Übersetzung scharf, was zu einem drastischen Rückgang der Finanzierung führte.26 Interne Kritik kam auch von KI-Forschern selbst: Marvin Minsky und Seymour Papert veröffentlichten 1969 eine Buch-lange Kritik an Perzeptronen, den Grundlagen früher neuronaler Netze. Sie behaupteten, dass ein neuronales Netz mit mehr als einer Schicht nicht leistungsfähig genug wäre, um Intelligenz zu replizieren.26 Mit dieser Veröffentlichung wurde die vielversprechende Idee eines selbstlernenden Netzwerks – das Perzeptron – nachhaltig diskreditiert und die Anfänge des Konnektivismus auf Eis gelegt.6
Der Lighthill-Report (1973) für den British Science Research Council gab eine sehr pessimistische Einschätzung des Feldes ab, indem er feststellte, dass „in keinem Teil des Feldes die bisherigen Entdeckungen die damals versprochenen großen Auswirkungen erzielt haben“.26 Dies, zusammen mit dem Mansfield Amendment (das militärische Forschungsgelder von Grundlagenforschung auf angewandte Militärtechnologien umlenkte), führte zu einem drastischen Rückgang der KI-Finanzierung.26
Der zweite KI-Winter (ca. 1987-1993)
Nach einem kurzen Aufschwung in den 1980er Jahren, getragen von Expertensystemen und regelbasierter KI, folgte ein erneuter und sogar schwerwiegenderer Rückgang.6 Expertensysteme, die das Wissen von Spezialisten in Regelwerken bündelten und in eng abgegrenzten Bereichen erfolgreich waren 4, stießen an ihre Grenzen.28
Sie erwiesen sich als zu komplex, schwer skalierbar und anpassungsfähig an neue Probleme.25 Der Aufbau und die Pflege der Wissensbasis waren enorm aufwendig.30 Die Nichterfüllung der hohen Erwartungen führte zu einem Vertrauensverlust und einem Einbruch der Finanzierung, was viele KI-Firmen in den Bankrott trieb.29
Das Scheitern des japanischen „Computerprojekts der 5. Generation“ von 1981, das innovative Computer mit parallelen Berechnungen und logischer Programmierung entwickeln sollte, trug ebenfalls zur Ernüchterung bei.30 Die Ziele erwiesen sich als zu ehrgeizig und die Erwartungen als unrealistisch hoch.30
Die KI-Winter waren nicht nur Perioden des Rückgangs, sondern auch kritische Lernphasen, die die Forschung dazu zwangen, ihre Ansätze zu überdenken und realistischere Ziele zu setzen. Die wiederkehrenden Zyklen von Hype und Ernüchterung, die in den Forschungsmaterialien beschrieben werden 23, verdeutlichen, dass der Fortschritt in der KI nicht linear verläuft. Die Kritiken (ALPAC, Minsky/Papert, Lighthill) und die Finanzierungskürzungen (Mansfield Amendment) wirkten als Korrekturmechanismen, die das Feld dazu zwangen, sich seinen Limitationen zu stellen.26 Diese schmerzhafte Selbstreflexion, obwohl sie zu reduzierten Mitteln führte, legte den Grundstein für zukünftige, robustere Ansätze, indem sie aufzeigte, was nicht funktionierte und warum. Dies beweist, dass der Fortschritt iterativ und adaptiv ist, nicht einfach nur eine stetige Aufwärtsbewegung.
Die folgende Tabelle fasst die beiden KI-Winter zusammen:
Tabelle 2: Die KI-Winter im Überblick
| Winter-Periode | Hauptursachen | Schlüsselkritiken / Ereignisse | Auswirkungen auf die Forschung |
| Erster KI-Winter (ca. 1974-1980) | Überzogene Erwartungen, technische Limitationen (Rechenleistung, Speicher), Programme ohne echtes Verständnis 17 | ALPAC-Report (Maschinelle Übersetzung), Minsky & Papert (Kritik an Perzeptronen), Lighthill-Report, Mansfield Amendment 6 | Drastischer Finanzierungsrückgang, Forschungsprojekte auf Eis gelegt, Vertrauensverlust, Fokus auf symbolische KI stagnierte 24 |
| Zweiter KI-Winter (ca. 1987-1993) | Limitationen von Expertensystemen (Skalierbarkeit, Wartung), Scheitern des japanischen 5. Generationsprojekts, erneute Nichterfüllung von Erwartungen 28 | Expertensysteme als zu komplex und unflexibel erkannt, Mansfield Amendment (erneut) 25 | Erneuter Finanzierungsrückgang, viele KI-Firmen insolvent, tiefe Skepsis gegenüber KI-Zukunft, Fokus auf Grundlagenforschung blieb bestehen 29 |
Diese Tabelle kondensiert die komplexen Informationen über die KI-Winter und macht sie visuell leicht verständlich. Sie ermöglicht es dem Leser, die wiederkehrenden Muster von Hype und Ernüchterung in der KI-Geschichte schnell zu erfassen. Durch die Gegenüberstellung von Ursachen und Auswirkungen wird die kausale Beziehung zwischen überzogenen Erwartungen, technischen Grenzen und den daraus resultierenden Finanzierungsengpässen deutlich. Dies hilft, die Lehren aus der Vergangenheit zu verdeutlichen und zu verstehen, warum die KI-Entwicklung nicht linear verläuft, sondern von Zyklen geprägt ist.
V. Die Renaissance der KI: Neue Paradigmen und Durchbrüche
Trotz der Perioden der Ernüchterung erlebte die KI ab den 1990er Jahren eine beeindruckende Renaissance, angetrieben durch neue Paradigmen und technologische Fortschritte, die zu den heutigen leistungsfähigen Systemen führten.
A. Maschinelles Lernen und Neuronale Netze
Die Forschung an künstlichen neuronalen Netzen stagnierte nach 1969, als Marvin Minsky und Seymour Papert bewiesen, dass einlagige Netze bestimmte Funktionen nicht berechnen konnten.32 Ein neuer Aufschwung begann jedoch 1982, als Paul Werbos die Backpropagation beschrieb, ein Verfahren, das das Training mehrschichtiger neuronaler Netze ermöglichte.31
Die 1990er Jahre brachten weitere Fortschritte mit der Entwicklung von Support Vector Machines (SVMs) und rekurrenten neuronalen Netzen (RNNs).32 Ab den 2000er Jahren gewann Maschinelles Lernen zunehmend an öffentlicher Anerkennung, angetrieben durch die kontinuierliche Zunahme an Rechenleistung und verfügbaren Daten.32
Deep Learning: Revolutionäre Fortschritte: Ein großer Durchbruch erfolgte 2006, als Geoffrey Hinton et al. eine Methode zum Training mehrschichtiger neuronaler Netze zur Erkennung handgeschriebener Zahlen mit über 98 % Genauigkeit beschrieben – der Beginn des Deep Learning.32 Zwischen 2009 und 2012 gewannen rekurrenten und tiefen Feed-Forward-Netzwerke von Jürgen Schmidhubers Forschungsgruppe eine Reihe internationaler Wettbewerbe in der Mustererkennung.32
Im Jahr 2012 gewann ein neuronales Netzwerk die ImageNet-Challenge mit einer Fehlerrate von nur 15,3 %, was als großer Moment für die KI galt.34 2015 trainierte DeepMind ein Netzwerk, klassische Atari-Spiele zu spielen.35 2016 besiegte AlphaGo den weltbesten Go-Spieler, was einen entscheidenden Wendepunkt markierte und die Fantasie der Menschen weltweit beflügelte.30 Dies bewies, dass eine Maschine einen Menschen bei einer Aufgabe übertreffen kann, die komplexe Entscheidungen über viele Schritte hinweg erfordert.31
2017 führte ein Google-Forschungsteam die Transformer-Architektur ein, die einen Aufmerksamkeitsmechanismus nutzt und den Trainingsaufwand für Sprachmodelle erheblich reduzierte.32 Diese Architektur ist die Grundlage für viele moderne Large Language Models (LLMs).
Der Durchbruch des Deep Learning ist eine direkte Folge der exponentiellen Zunahme von Rechenleistung und Datenverfügbarkeit, die es ermöglichten, Algorithmen wie Backpropagation, die schon länger bekannt waren, endlich effektiv einzusetzen.32 Die theoretischen Algorithmen existierten, aber ihre praktische Nützlichkeit wurde erst durch Fortschritte in der Hardware und Dateninfrastruktur freigesetzt. Dies unterstreicht, dass der Fortschritt in der KI nicht allein von algorithmischer Innovation abhängt, sondern auch vom unterstützenden technologischen Ökosystem.
Aktuelle Fähigkeiten und Limitationen: Heutige ML-Systeme können Daten gruppieren (Clustering), Objekte klassifizieren, Werte schätzen und vorhersagen, Bilder und Sprache erkennen und Informationen aus Texten extrahieren.36 Sie sind in der Lage, radiologische Bilder so gut wie Mediziner zu analysieren, selbst KI-Software zu schreiben und in komplexen Spielen wie Go und Poker gegen Menschen zu gewinnen.36
Trotz dieser Erfolge bestehen Limitationen: ML-Modelle benötigen oft große Mengen hochwertiger Trainingsdaten.32 Die Transparenz und Erklärbarkeit sind bei tiefen neuronalen Netzen oft nicht gegeben („Black Box“-Problem), was die Nachvollziehbarkeit von Entscheidungen erschwert.32 Zudem sind sie anfällig für „adversarial attacks“ (Gegenangriffe) und können Schwierigkeiten mit gesundem Menschenverstand oder der Interpretation komplexer, emotionaler Nuancen haben.34 Beispielsweise können subtile, für Menschen nicht wahrnehmbare Änderungen an Bildern dazu führen, dass ein trainiertes CNN eine falsche Klassifizierung vornimmt.37
B. Spezialisierte KI-Bereiche
Die Renaissance der KI führte auch zu einer starken Spezialisierung in verschiedene Bereiche, die jeweils spezifische Facetten menschlicher Intelligenz adressieren.
Natürliche Sprachverarbeitung (NLP)
NLP ist die Fähigkeit von Maschinen, menschliche Sprache zu verstehen, zu interpretieren und zu generieren.38 Ihre Entwicklung lässt sich in regelbasierte Ansätze (ab den 1960ern, z.B. der Chatbot ELIZA 22), statistische Verfahren (ab den 1980ern) und die Ära des Deep Learning (ab den 2010ern) unterteilen.22
Schlüsseltechniken umfassen die Tokenisierung (Zerlegung von Text in bedeutungstragende Einheiten), das Parsing (Analyse der grammatikalischen Struktur), die Lemmatisierung (Reduktion auf die Grundform), die Named Entity Recognition (NER) zur Identifizierung von Entitäten wie Personen oder Orten und die Stimmungsanalyse.38
Moderne NLP-Modelle wie BERT, GPT und andere Transformer-Architekturen haben die Sprachverarbeitung revolutioniert.39 Sie ermöglichen Anwendungen von Chatbots und Übersetzungsdiensten bis hin zu Textanalysen und der automatischen Generierung von Inhalten.38
Herausforderungen bleiben jedoch bestehen: sprachliche Mehrdeutigkeit, Kontextabhängigkeit, die Erkennung von Sarkasmus und Ironie sowie kulturelle Nuancen stellen weiterhin große Hürden dar.38 Zudem können NLP-Systeme Bias aus ihren Trainingsdaten übernehmen, was zu ethischen Problemen führen kann.39
Computer Vision
Die Computer Vision begann in den frühen 1960er Jahren mit Pionierarbeiten zur 3D-Objekterkennung durch Lawrence G. Roberts und der Entwicklung von Algorithmen zur Kantenerkennung, wie dem Sobel-Operator.40 In den 1970er Jahren entwickelte sich die Mustererkennung zu einem Schlüsselbereich, der Methoden zur Erkennung von Formen, Texturen und Objekten in Bildern hervorbrachte.40
Der transformative Einfluss von Deep Learning und Convolutional Neural Networks (CNNs) war entscheidend für den Durchbruch der Computer Vision.40 CNNs lernen hierarchische Muster in Bildern durch Faltungsschichten, Aktivierungsfunktionen und Pooling-Schichten.40
Wichtige Architekturen wie LeNet (1989), AlexNet (2012), VGGNet (2014), ResNet (2015) und YOLO haben die Bilderkennung und Objektdetektion revolutioniert.40 Anwendungen reichen von der medizinischen Diagnostik (z.B. Tumorerkennung) über die Verkehrsüberwachung bis hin zur industriellen Produktion und Umweltüberwachung.40
Robotik und Autonomie
Die Geschichte der Robotik reicht von frühen Automaten wie Yan Shis mechanischer Figur in der Antike und Al-Jazaris humanoiden Automaten (1206) bis zu Leonardo da Vincis Roboterentwürfen.41
Frühe autonome Maschinen wie Leonardo Torres Quevedos El Ajedrecista (1912) konnten Schach spielen und "Urteile" fällen.41 Der Begriff "Roboter" wurde 1921 durch das Theaterstück R.U.R. populär.41
Die Integration von KI in Robotersysteme ermöglicht es Robotern, autonom mit ihrer Umgebung zu interagieren und Entscheidungen auf Basis ihrer Programmierung zu treffen, im Gegensatz zu reiner Fernsteuerung oder Automation.41 Moderne Roboter nutzen KI für Aufgaben, die Wahrnehmung, Lernen und Entscheidungsfindung in komplexen Umgebungen erfordern, z.B. autonome Fahrzeuge, Drohnen und Haushaltsroboter.41 Die aktuelle Forschung konzentriert sich auf die Mensch-Roboter-Kollaboration und lebenslanges Lernen.41
Reinforcement Learning
Reinforcement Learning (RL) hat zwei Hauptstränge: das Lernen durch Versuch und Irrtum, das in der Psychologie des Tierlernens (Thorndikes „Law of Effect“) wurzelt, und die optimale Steuerung, die auf Bellmans dynamischer Programmierung basiert.42 Ein dritter, weniger ausgeprägter Strang sind die Temporal-Difference-Methoden.42
Das Konzept des „credit assignment problem“ (Minsky, 1961), also die Frage, wie der Erfolg auf die vielen beteiligten Entscheidungen verteilt wird, ist zentral für RL-Methoden.42 Frühe Experimente wie Donald Michies MENACE (1961) für Tic-Tac-Toe zeigten das Potenzial des Trial-and-Error-Lernens.42
Die Konvergenz dieser Stränge erfolgte 1989 mit Chris Watkins' Q-Learning, das frühere Arbeiten aus allen drei Bereichen integrierte.42 Bekanntheit erlangte das Feld 1992 mit Gerry Tesauros TD-Gammon, einem Backgammon-Programm, das durch RL lernte.42
Wissensrepräsentation (KR)
Wissensrepräsentation (KR) ist ein zentraler Bereich der KI, der sich damit befasst, wie Wissen über die Welt formalisiert und von Maschinen verarbeitet werden kann.43 Ziel ist es, Wissen so zu strukturieren, dass Computer es verstehen, um darauf basierend fundierte Entscheidungen zu treffen und Probleme zu lösen.43
Methoden umfassen formale Logiken (z.B. Beschreibungslogiken im Semantic Web), Semantische Netze (grafische Darstellung von Wissen als Knoten und Kanten für Beziehungen), Frames (Datenstrukturen zur Unterteilung von Wissen in stereotypen Situationen, von Marvin Minsky 1974 vorgeschlagen) und Ontologien (präzise Strukturierung für umfassende Domänen).43 KR ist entscheidend, wenn Maschinen Entscheidungen auf Basis von Wissen treffen müssen, ohne dass ein Mensch jede einzelne Frage beantwortet.43
Die Spezialisierung der KI in verschiedene Bereiche wie NLP, Computer Vision, Robotik, Reinforcement Learning und Wissensrepräsentation spiegelt die Komplexität menschlicher Intelligenz wider. Menschliche Intelligenz ist nicht durch einen einzigen Ansatz abzubilden, sondern erfordert eine modulare und interdisziplinäre Forschung. Diese Aufteilung in spezialisierte Sub-Disziplinen ermöglicht tiefere Fortschritte in einzelnen Bereichen, verdeutlicht aber auch die anhaltende Herausforderung, diese spezialisierten Intelligenzen zu einer allgemeineren KI zu integrieren.
Die folgende Tabelle bietet einen strukturierten Überblick über die verschiedenen KI-Paradigmen und ihre Anwendungsbereiche:
Tabelle 3: Aktuelle KI-Paradigmen und ihre Anwendungsbereiche
| Paradigma / Bereich | Kernkonzept | Schlüssel-Durchbrüche / Beispiele | Aktuelle Herausforderungen |
| Maschinelles Lernen (ML) | Systeme lernen aus Daten, anstatt explizit programmiert zu werden. | Perzeptron, Backpropagation, Random Forests, Deep Learning (ImageNet, AlphaGo) 30 | Datenbedarf, Interpretierbarkeit ("Black Box"), Robustheit, Ressourcen 32 |
| Neuronale Netze (NN) | Vom Gehirn inspirierte Modelle zur Mustererkennung und Datenverarbeitung. | Mehrschichtige Netze, CNNs, RNNs, Transformer-Architekturen 32 | Transparenz, Anfälligkeit für "adversarial attacks", Verständnis emotionaler Nuancen 34 |
| Natürliche Sprachverarbeitung (NLP) | Maschinen verstehen, interpretieren und generieren menschliche Sprache. | ELIZA, statistische Verfahren, BERT, GPT-Modelle 22 | Sprachliche Mehrdeutigkeit, Kontextverständnis, kulturelle Nuancen, Bias 38 |
| Computer Vision (CV) | Maschinen "sehen" und interpretieren visuelle Daten. | Kantenerkennung, Mustererkennung, CNNs (AlexNet, ResNet, YOLO) 40 | Semantisches Verständnis von Szenen, Lernen mit wenig Daten, Kombinieren multimodaler Inhalte 36 |
| Robotik | Entwicklung von Maschinen, die physische Aufgaben ausführen und mit der Umgebung interagieren. | Frühe Automaten, autonome Roboter (El Ajedrecista), industrielle Roboter, humanoide Roboter 41 | Mensch-Roboter-Kollaboration, Anpassungsfähigkeit an unbekannte Umgebungen, ethische Aspekte der Autonomie 41 |
| Reinforcement Learning (RL) | Agenten lernen durch Versuch und Irrtum aus Belohnungen und Bestrafungen. | MENACE, BOXES, Q-Learning, TD-Gammon, AlphaGo 42 | Effizienz des Lernens, Generalisierbarkeit, "Credit Assignment Problem" 42 |
| Wissensrepräsentation (KR) | Formalisierung von Wissen, damit Maschinen es verarbeiten und nutzen können. | Formale Logiken, Semantische Netze, Frames, Ontologien 43 | Hoher Modellierungsaufwand, Umgang mit vagem/unsicherem Wissen, Wiederverwendung von Wissen 43 |
Diese Tabelle bietet einen strukturierten Überblick über die verschiedenen „Abzweigungen“ der KI und hilft, die Vielfalt des KI-Feldes zu visualisieren und die spezifischen Beiträge jedes Paradigmas zum Gesamtfortschritt der KI hervorzuheben. Durch die Auflistung von Durchbrüchen und Herausforderungen für jeden Bereich wird deutlich, dass KI kein monolithisches Konzept ist, sondern ein Zusammenspiel spezialisierter Disziplinen.
VI. KI heute und morgen: Wo stehen wir und wohin geht die Reise?
Die Künstliche Intelligenz hat in den letzten Jahren eine beispiellose Entwicklung durchgemacht und ist zu einer transformativen Kraft geworden, die Wirtschaft, Gesellschaft und Arbeitswelt tiefgreifend beeinflusst.
Aktueller Stand: Large Language Models (LLMs) und generative KI als Game Changer
Die jüngsten Fortschritte in der KI werden maßgeblich durch die rasante Entwicklung im Bereich des Maschinellen Lernens und insbesondere des Deep Learnings getrieben.30 Large Language Models (LLMs) und generative KI-Systeme wie ChatGPT, Firebird 23 und DALL-E 2 haben neue Maßstäbe gesetzt und können glaubhafte Texte oder fantasievolle Bilder generieren.2 Diese Systeme sind oft multimodal, das heißt, sie können mit Bild- und Textdaten gleichzeitig trainiert werden und diese verknüpfen, um beispielsweise passende Untertitel zu Bildern zu erzeugen.2
Generative KI wird als möglicher Weg hin zu einer starken KI gesehen und hat das Potenzial, den Arbeitsmix zu verändern und die Art der Arbeit für Wissensarbeiter erheblich zu beeinflussen.1 Die breite Akzeptanz dieser Technologien zeigt sich auch in der Wirtschaft: Im Jahr 2024 nutzte bereits jedes fünfte Unternehmen in Deutschland KI, was einem Anstieg von 8 Prozentpunkten innerhalb eines Jahres entspricht.51 Großunternehmen setzen KI dabei deutlich häufiger ein als kleine und mittlere Unternehmen.51
Wirtschaftliches Potenzial und Auswirkungen auf Gesellschaft und Arbeitswelt
Das aktuelle Wirtschaftspotenzial von KI wird auf 11,0-17,7 Billionen USD geschätzt, mit einem prognostizierten Wachstum von 20 % bis 2030.1 KI kann Unternehmen helfen, Kosten um bis zu 20 % zu senken und den Umsatz um bis zu 10 % zu steigern.1
Automatisierung und Arbeitsplatzveränderungen: KI automatisiert zunehmend Routine- und manuelle Aufgaben, was Berufe wie Kundenservice, Büroarbeit und Datenverarbeitung einem höheren Automatisierungsrisiko aussetzt.52 Experten sind sich jedoch einig, dass KI Jobs nicht vollständig ersetzen, sondern vielmehr die Art und Weise verändern wird, wie Aufgaben ausgeführt werden.52 Eine McKinsey-Forschung zeigt, dass bis zu 50 % der Aufgaben in bestimmten Branchen automatisiert werden könnten, aber nur etwa 5 % der Jobs vollständig ersetzt.52
Arbeitsplatzschaffung und Anpassung: Während KI einige Jobs verdrängen kann, schafft sie auch neue Rollen, insbesondere in Bereichen wie KI-Management, Datenwissenschaft und Cybersicherheit.52 Das Weltwirtschaftsforum (WEF) prognostiziert, dass bis 2025 weltweit 97 Millionen neue Jobs durch KI entstehen könnten, was die 85 Millionen verdrängten Arbeitsplätze ausgleicht.52 Diese neuen Rollen erfordern fortgeschrittenere Fähigkeiten wie technisches Fachwissen, Problemlösung und Kreativität, was Unternehmen dazu veranlasst, in Schulung und Entwicklung zu investieren.52
Löhne und Ungleichheit: Die Auswirkungen von KI auf Löhne und Ungleichheit sind vielschichtig. KI kann die Produktivität steigern, aber die Vorteile könnten unverhältnismäßig hochqualifizierte Arbeitskräfte und Kapitalbesitzer begünstigen, was die Lohnunterschiede möglicherweise vergrößert.52 Geringqualifizierte Arbeitnehmer sind anfälliger für Arbeitsplatzverluste, und ohne Umschulungsprogramme könnte die Ungleichheit zunehmen.52
Mitarbeiterzufriedenheit: KI hat das Potenzial, die Mitarbeiterzufriedenheit und das Wohlbefinden zu verbessern, indem sie alltägliche Aufgaben reduziert und den Mitarbeitern ermöglicht, sich auf sinnvollere, wertschöpfende Aktivitäten zu konzentrieren.52
Ethische Überlegungen und Herausforderungen
Die rasante Entwicklung und Integration von KI in den Alltag bringt auch eine Reihe wichtiger ethischer Überlegungen und Herausforderungen mit sich.
Bias und Fairness: KI-Systeme können Vorurteile aus ihren Trainingsdaten übernehmen, was zu ungerechter Behandlung bestimmter Gruppen führen kann.52 Dies ist besonders relevant für gehostete LLMs, die Bias aus ihren Trainingsdaten reproduzieren können.52 Maßnahmen zur Minderung umfassen die Verwendung vielfältiger und repräsentativer Datensätze, regelmäßige Überprüfungen und Techniken wie Re-Sampling oder Neugewichtung, um die Trainingsdaten fairer zu gestalten.53
Datenschutz und Datensicherheit: KI-Systeme verarbeiten oft sensible Daten, was robuste Richtlinien und Praktiken zum Schutz personenbezogener Daten erfordert.53 Die Einhaltung von Vorschriften wie der DSGVO (General Data Protection Regulation) ist unerlässlich, da sie Richtlinien für die Erhebung und Verarbeitung personenbezogener Daten festlegt.53 Transparenz bei der Datenerhebung, -nutzung und -speicherung ist ebenfalls wichtig.53
Transparenz und Erklärbarkeit: Das „Black Box“-Problem bei Deep Learning 32 erschwert das Verständnis, wie KI-Systeme zu Entscheidungen kommen. Dies ist besonders in Bereichen, wo Gesetzgebung Nachvollziehbarkeit erfordert (z.B. bei der Kreditvergabe), eine große Herausforderung.32
Regulierung: Die zunehmende Integration von KI in den Alltag führt zu Forderungen nach Regulierung, um einen verantwortungsvollen und ethischen Einsatz sicherzustellen.29 Während Regulierung notwendig ist, könnte sie auch das Tempo der KI-Entwicklung verlangsamen.29
Die aktuelle „KI-Frühling“ mit generativer KI und LLMs stellt die Gesellschaft vor eine neue, dringende Herausforderung: Wie können wir die transformative Kraft dieser Technologien nutzen, während wir gleichzeitig ihre inhärenten Risiken (Bias, Black-Box, Arbeitsplatzwandel) mindern und eine ethische, menschenzentrierte Entwicklung sicherstellen? Die Forschungsmaterialien heben das immense wirtschaftliche Potenzial 1 und die weit verbreitete Akzeptanz der aktuellen KI hervor.51 Gleichzeitig werden ausführlich ethische Bedenken wie Bias 52, Datenschutz 53, Arbeitsplatzverdrängung 52 und das „Black Box“-Problem 32 thematisiert. Dies erzeugt eine kritische Spannung: Der Wunsch nach Innovation steht dem Bedarf an verantwortungsvoller Governance gegenüber. Die Frage ist nicht mehr, ob KI die Gesellschaft verändern wird, sondern wie diese Veränderung gesteuert werden kann, um den Nutzen zu maximieren und Schäden zu minimieren, was proaktive Maßnahmen wie Regulierung und Umschulung erfordert.29
Zukünftige Trends und Ausblick
Die Zukunft der KI ist vielversprechend, mit laufenden Forschungen, die ihre Fähigkeiten und Anwendungen weiter verbessern werden.38 Es wird erwartet, dass KI-Systeme in Zukunft noch besser darin werden, komplexe Situationen zu interpretieren, subtile emotionale Nuancen zu verstehen und kreative Aufgaben zu lösen.34
Die Integration von KI in bestehende Systeme, die Bewältigung hoher Rechenleistungsanforderungen und die Notwendigkeit umfangreicher, hochwertiger Trainingsdaten bleiben technische Herausforderungen, an denen intensiv gearbeitet wird.34
Der Trend geht klar zu einer „kollaborativen Intelligenz“, in der KI und Mensch ihre jeweiligen Stärken kombinieren: KI für Geschwindigkeit, Volumen und Konsistenz, während Menschen Urteilsvermögen, Kreativität und Empathie einbringen.54 Diese Partnerschaft wird sich weiter vertiefen, da KI-Tools interaktiver und reaktionsfähiger auf Feedback werden.54 Die Bedeutung der KI-Winter ist nicht nur ein Rückblick auf die Vergangenheit, sondern bietet eine Chance zur weiteren Entwicklung neuer Methoden und Technologien.23
Fazit: Die unaufhaltsame Evolution der Künstlichen Intelligenz
Von den philosophischen Träumen der Antike über mechanische Rechenmaschinen bis hin zu den komplexen neuronalen Netzen und generativen KI-Systemen von heute hat die Künstliche Intelligenz einen bemerkenswerten Weg zurückgelegt. Diese Reise war geprägt von visionären Ideen, bahnbrechenden Entdeckungen und Phasen der Ernüchterung, die als „KI-Winter“ bekannt wurden. Doch jede dieser Phasen trug dazu bei, das Feld zu reifen und neue Wege für den Fortschritt zu ebnen.
Heute stehen wir an einem Punkt, an dem KI nicht mehr nur ein Forschungsgebiet ist, sondern eine transformative Kraft, die unsere Wirtschaft, Gesellschaft und unser tägliches Leben grundlegend verändert. Die aktuellen Fortschritte in Bereichen wie Maschinelles Lernen, NLP und Computer Vision sind beeindruckend, bringen aber auch neue Herausforderungen mit sich – von ethischen Fragen wie Bias und Datenschutz bis hin zu den Auswirkungen auf den Arbeitsmarkt.
Die Geschichte der KI lehrt, dass der Fortschritt selten linear verläuft und dass überzogene Erwartungen oft zu Rückschlägen führen können. Doch sie zeigt auch die unermüdliche menschliche Neugier und den Drang, Maschinen zu schaffen, die lernen, denken und uns in unserer Arbeit und unserem Leben unterstützen. Die Zukunft der KI wird eine gemeinsame Reise sein – eine, die verantwortungsvolle Innovation, kontinuierliches Lernen und eine enge Zusammenarbeit zwischen Mensch und Maschine erfordert, um ihr volles Potenzial zum Wohle aller zu entfalten.
Referenzen
- www.haw-landshut.de, Zugriff am Juni 3, 2025, https://www.haw-landshut.de/static/ITZ/Bilder/Veranstaltungen/LLF/Beitraege_LL/2024/LL_5_2024_KI-Wirtschaft_Schwertl.pdf
- Künstliche Intelligenz verstehen: Definition, Funktion, Historie und Zukunft - Tableau, Zugriff am Juni 3, 2025, https://www.tableau.com/de-de/data-insights/ai/what-is
- Geschichte der Künstlichen Intelligenz (KI) - TheMatch.AI, Zugriff am Juni 3, 2025, https://thematch.ai/de/blog/eine-reise-durch-die-geschichte-der-kuenstlichen-intelligenz/
- Geschichte der KI, Zugriff am Juni 3, 2025, https://www.tobiasknuth.de/blog/history-of-ai/
- Automaten in der Zeit der Romantik - E.T.A. Hoffmann Portal, Zugriff am Juni 3, 2025, https://etahoffmann.staatsbibliothek-berlin.de/erforschen/romantik/automaten-romantik/
- bitdynamo Geschichte der Künstlichen Intelligenz - bitdynamo, Zugriff am Juni 3, 2025, https://bitdynamo.com/geschichte-der-kuenstlichen-intelligenz/
- Geschichte und Entwicklung von künstlicher Intelligenz - gridscale, Zugriff am Juni 3, 2025, https://gridscale.io/blog/geschichte-und-entwicklung-von-kuenstlicher-intelligenz/
- Weihwasser auf Knopfdruck und weitere 8 wilde Automaten der Antike - ingenieur.de, Zugriff am Juni 3, 2025, https://www.ingenieur.de/technik/fachbereiche/rekorde/automaten-in-der-antike-das-konnten-die-ersten-maschinen-der-menschheit/
- Automaten und Roboter im Mittelalter | curiositas, Zugriff am Juni 3, 2025, https://curiositas-mittelalter.blogspot.com/2016/12/automaten-roboter.html
- Chronologie der Entwicklung von Rechenhilfsmitteln in ... - Lernhelfer, Zugriff am Juni 3, 2025, https://www.lernhelfer.de/schuelerlexikon/mathematik-abitur/artikel/chronologie-der-entwicklung-von-rechenhilfsmitteln
- Geschichte der Automaten – Wikipedia, Zugriff am Juni 3, 2025, https://de.wikipedia.org/wiki/Geschichte_der_Automaten
- www.olln-handwarkers.de, Zugriff am Juni 3, 2025, https://www.olln-handwarkers.de/wp-content/uploads/2021/04/2.-Entwicklung-ReMa_03.pdf
- History of Computing - Texas Computer Science, Zugriff am Juni 3, 2025, https://www.cs.utexas.edu/~mitra/csSpring2014/cs303/lectures/history.html
- Die Geschichte der KI: von der Turingmaschine bis Deep Learning - robominds, Zugriff am Juni 3, 2025, https://www.robominds.de/blog/die-geschichte-der-ki-von-der-turingmaschine-bis-deep-learning
- The Definition of the Turing Test - Time, Zugriff am Juni 3, 2025, https://time.com/collection_hub_item/definition-of-turing-test/
- Turing test - Wikipedia, Zugriff am Juni 3, 2025, https://en.wikipedia.org/wiki/Turing_test
- Die Geschichte der KI: Ein Rückblick von den Ursprüngen bis zur Moderne - IT-P GmbH, Zugriff am Juni 3, 2025, https://www.it-p.de/blog/geschichte-ki/
- Artificial Intelligence (AI) Coined at Dartmouth, Zugriff am Juni 3, 2025, https://home.dartmouth.edu/about/artificial-intelligence-ai-coined-dartmouth
- Dartmouth workshop - Wikipedia, Zugriff am Juni 3, 2025, https://en.wikipedia.org/wiki/Dartmouth_workshop
- ELIZA - Wikipedia, Zugriff am Juni 3, 2025, https://en.wikipedia.org/wiki/ELIZA
- ELIZA Reanimated: The world's first chatbot restored on the world's first time sharing system, Zugriff am Juni 3, 2025, https://www.researchgate.net/publication/387975619_ELIZA_Reanimated_The_world's_first_chatbot_restored_on_the_world's_first_time_sharing_system
- Die Geschichte hinter ChatGPT: Wie Transformer-Architekturen die KI-Welt erobern - Business -Software- und IT-Blog - Wir gestalten digitale Wertschöpfung, Zugriff am Juni 3, 2025, https://blog.doubleslash.de/software-technologien/kuenstliche-intelligenz/die-geschichte-hinter-chatgpt-wie-transformer-architekturen-die-ki-welt-erobern
- KI-Winter – akute Gefahr oder langfristige Chance? - TenMedia GmbH, Zugriff am Juni 3, 2025, https://www.tenmedia.de/de/blog/kategorie/sonstiges/ki-winter
- KI-Winter | mindsquare, Zugriff am Juni 3, 2025, https://mindsquare.de/knowhow/ki-winter/
- What Is AI Winter? | Built In, Zugriff am Juni 3, 2025, https://builtin.com/artificial-intelligence/ai-winter
- The First AI Winter (1974–1980) — Making Things Think: How AI ..., Zugriff am Juni 3, 2025, https://www.holloway.com/g/making-things-think/sections/the-first-ai-winter-19741980
- Maschinelle Übersetzung – Geschichte und aktuelle Entwicklung - dictaJet, Zugriff am Juni 3, 2025, https://www.dictajet.de/maschinelle-uebersetzung-geschichte-und-aktuelle-entwicklung/
- demandifymedia.com, Zugriff am Juni 3, 2025, https://demandifymedia.com/ai-winter-a-comparative-analysis-of-the-first-and-second-ai-winters/#:~:text=The%20Second%20AI%20Winter%20(1987%2D1993)&text=This%20period%20followed%20a%20brief,1980s%2C%20proved%20limited%20in%20scope.
- AI Winter: The Reality Behind Artificial Intelligence History, Zugriff am Juni 3, 2025, https://aibc.world/learn-crypto-hub/ai-winter-history/
- KI | Die Geschichte der Künstlichen Intelligenz | mebis Magazin, Zugriff am Juni 3, 2025, https://mebis.bycs.de/beitrag/ki-geschichte-der-ki
- application.wiley-vch.de, Zugriff am Juni 3, 2025, https://application.wiley-vch.de/books/sample/3527722610_c01.pdf
- Maschinelles Lernen – Wikipedia, Zugriff am Juni 3, 2025, https://de.wikipedia.org/wiki/Maschinelles_Lernen
- Die Geschichte des maschinellen Lernens - eine Zeitreise - Clickworker.de, Zugriff am Juni 3, 2025, https://www.clickworker.de/kunden-blog/geschichte-des-maschinellen-lernens/
- Neuronale Netzwerke der nächsten Generation: Was uns erwartet, Zugriff am Juni 3, 2025, https://ki-trainingszentrum.com/neuronale-netzwerke-der-naechsten-generation-was-uns-erwartet/
- News Feature: What are the limits of deep learning? - PMC, Zugriff am Juni 3, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC6347705/
- www.iais.fraunhofer.de, Zugriff am Juni 3, 2025, https://www.iais.fraunhofer.de/content/dam/iais/publikationen/studien-und-whitepaper/2018/Fraunhofer_Maschinelles_Lernen.pdf
- Limitations of Deep Learning and strategic observations ..., Zugriff am Juni 3, 2025, https://www.datasciencecentral.com/limitations-of-deep-learning-and-strategic-observations/
- Was ist natürliche Sprachverarbeitung (NLP)? Ein Leitfaden für ..., Zugriff am Juni 3, 2025, https://www.datacamp.com/de/blog/what-is-natural-language-processing
- Was ist Natural Language Processing (NLP)? - OMR, Zugriff am Juni 3, 2025, https://omr.com/de/reviews/contenthub/natural-language-processing
- Vision AI Geschichte: Von der Kantenerkennung bis zu YOLOv8, Zugriff am Juni 3, 2025, https://www.ultralytics.com/de/blog/a-history-of-vision-models
- Robotics - Wikipedia, Zugriff am Juni 3, 2025, https://en.wikipedia.org/wiki/Robotics
- 1.6 History of Reinforcement Learning - Rich Sutton, Zugriff am Juni 3, 2025, http://incompleteideas.net/book/ebook/node12.html
- Knowledge Representation - mindsquare AG, Zugriff am Juni 3, 2025, https://mindsquare.de/knowhow/knowledge-representation/
- Wissensrepräsentation: Grundlagen & Techniken - StudySmarter, Zugriff am Juni 3, 2025, https://www.studysmarter.de/studium/informatik-studium/kuenstliche-intelligenz-studium/wissensrepraesentation/
- Die zehn bedeutenden Technologien der deutschen KI-Geschichte / ki50, Zugriff am Juni 3, 2025, https://ki50.de/die-zehn-bedeutenden-technologien-der-deutschen-ki-geschichte/
- Semantic Networks - John Sowa, Zugriff am Juni 3, 2025, http://www.jfsowa.com/pubs/semnet.pdf
- What Are Semantic Networks? A Little Light History, Zugriff am Juni 3, 2025, https://poplogarchive.getpoplog.org/computers-and-thought/chap6/node5.html
- Marvin Minsky: The Visionary Behind the Confocal Microscope and the Father of Artificial Intelligence - PMC - PubMed Central, Zugriff am Juni 3, 2025, https://pmc.ncbi.nlm.nih.gov/articles/PMC11445717/
- Frame (artificial intelligence) - Wikipedia, Zugriff am Juni 3, 2025, https://en.wikipedia.org/wiki/Frame_(artificial_intelligence)
- Erkundung Neuronaler Netze: Ein Leitfaden für Anfänger, Zugriff am Juni 3, 2025, https://chat-gpt-schweiz.ch/neuronale-netze/
- Presse Jedes fünfte Unternehmen nutzt künstliche Intelligenz - Statistisches Bundesamt, Zugriff am Juni 3, 2025, https://www.destatis.de/DE/Presse/Pressemitteilungen/2024/11/PD24_444_52911.html
- Einsatz von KI: Vorteile, Herausforderungen & ethische Überlegungen, Zugriff am Juni 3, 2025, https://www.eficode.com/de/blog/einsatz-von-ki-vorteile-herausforderungen-ethische-ueberlegungen?hsLang=de
- Ethische KI: Verantwortungsvolle Innovation | Ultralytics, Zugriff am Juni 3, 2025, https://www.ultralytics.com/de/blog/the-ethical-use-of-ai-balances-innovation-and-integrity
- From Rule-Based to AI-Driven Translation: How Machine Translation Has Evolved, Zugriff am Juni 3, 2025, https://www.1stopasia.com/blog/from-rule-based-to-ai-driven-translation-how-machine-translation-has-evolved/
Interne Links
- LLMO: https://www.seowerk.de/news/llmo/
- Google AIO: https://www.seowerk.de/news/google-aio/
- SEO Agentur: https://www.seowerk.de/seo-agentur/
- Andere Leistungen: https://www.seowerk.de/leistungen/
Warum KI-freie Inhalte heute wichtiger sind denn je
Technologien wie ChatGPT oder Gemini erleichtern zwar die Massenproduktion von Texten, doch sie können menschliche Kreativität, Erfahrung und Empathie nicht ersetzen. Gerade in sensiblen Branchen wie Medizin, Finanzen, Recht, Beratung oder Luxusgüter sind echte, menschliche Texte ein unverzichtbares Qualitätsmerkmal.
Vertrauen, Authentizität und emotionale Bindung entstehen nicht durch Algorithmen – sie entstehen durch das Fingerspitzengefühl erfahrener Redakteure!
Branchen, in denen KI-freie Redaktion unverzichtbar ist
- Journalistische Beiträge und Interviews
- Medizinische Fachartikel
- Rechtliche Texte und Gutachten
- Premium- und Luxusmarken-Content
- Beratungsdienstleistungen
Ihre Vorteile mit rein menschlicher Content-Erstellung
- Individuelle Texte ohne KI
- Redaktion menschlicher Texte von erfahrenen Autoren
- Texterstellung ohne AI: Maßgeschneiderte Inhalte für Ihre Zielgruppe
- Sprachliche Feinheiten, die Maschinen nicht erfassen
- Emotional ansprechender und vertrauenswürdiger Content
Texte ohne KI – vielfältige Formate für jeden Bedarf
Unser Team bietet Ihnen ein breites Spektrum an redaktionellen Leistungen – selbstverständlich komplett ohne Einsatz von künstlicher Intelligenz:
- Magazine und Print-Publikationen
- Online-Artikel und Blogposts
- Newsletter und E-Mail-Marketing-Content
- Produktbeschreibungen für Online-Shops
- SEO-Texte und suchmaschinenoptimierte Artikel
- Fachaufsätze, Whitepaper und Expertenbeiträge
Jedes Textformat wird sorgfältig auf Ihre Zielgruppe, Ihre Markenbotschaft und die gewünschten SEO-Aspekte abgestimmt. Dabei integrieren wir relevante Keywords natürlich und wirkungsvoll, ohne die Lesbarkeit oder Authentizität Ihrer Inhalte zu beeinträchtigen.
Texterstellung ohne AI: Qualität hat ihren Preis
Es ist wichtig zu verstehen, dass hochwertige, menschlich verfasste Texte mehr Zeit, Know-how und Fingerspitzengefühl erfordern als KI-generierter Content.
Deshalb spiegeln sich die Qualität und Individualität auch in einer angemessenen Investition wider. Für Unternehmen, die auf langfristigen Erfolg und authentische Kommunikation setzen, zahlt sich dieser Schritt mehrfach aus.
„*“ zeigt erforderliche Felder an
Interne Links
- SEO Agentur: https://www.seowerk.de/seo-agentur/
- Andere Leistungen: https://www.seowerk.de/leistungen/
LLMs und Vektor-Datenbanken
Um die Funktionsweise von RAG-Systemen zu erläutern, ist es vorab wichtig, die Begriffe Large Language Model und Vektor-Datenbank zu verstehen. Large Language Models sind eine Art Algorithmus, der Deep-Learning-Techniken und große Datensätze verwendet, um Inhalte zu verstehen, zusammenzufassen, zu generieren und vorherzusagen. Gefüttert werden diese Modelle mit den sogenannten Trainingsdaten, auf deren Basis der Output generiert wird. Als Schnittstelle zwischen Nutzer und LLM fungieren sogenannte KI-Chatbots wie ChatGPT, Google Gemini und Google AIOs (das Optimieren auf Platzierungen in Chatbots nennt man übrigens LLMO). Je ausführlicher und detaillierter die Trainingsdaten, desto leistungsfähiger das Modell. Zum Vergleich: ChatGPT 3 wurde mit 175 Milliarden Parametern gefüttert, während ChatGPT 4 mit 100 Billionen Parametern gefüttert wurde. Entsprechend leistungsfähiger ist ChatGPT 4.
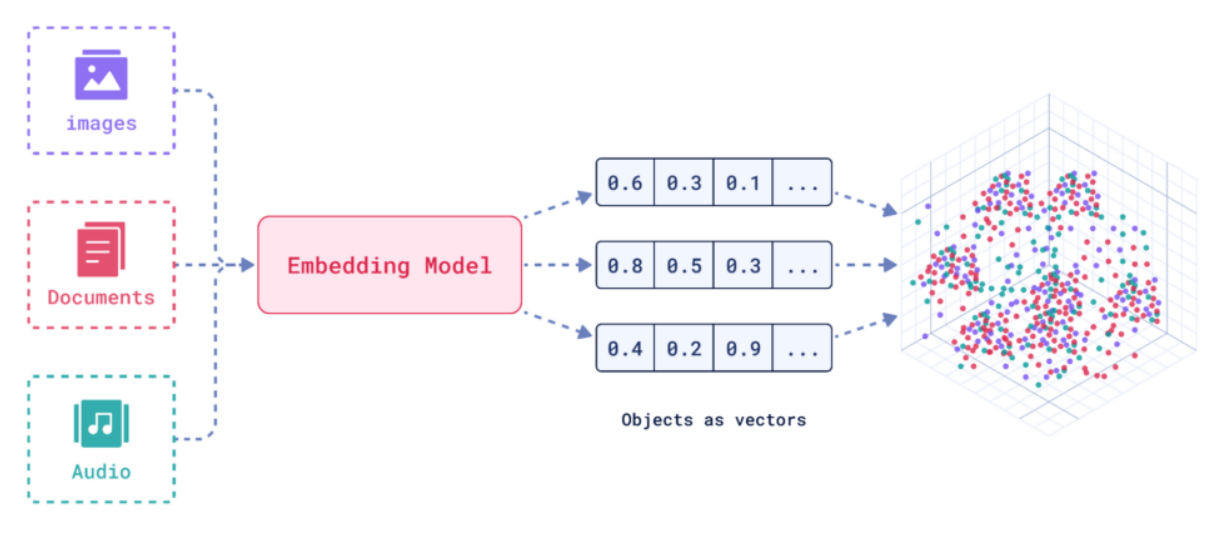
Die hier erläuterten Trainingsdaten werden über ein KI-basiertes Einbettungsmodell auf Basis ihrer Bedeutung und ihres Kontextes in Vektor-Embeddings, also mehrdimensionale Punkte in einem Koordinatensystem, umgewandelt. Mithilfe der Vektoren lassen sich unterschiedliche Datentypen wie Bilder, Dokumente oder Audio-Dateien miteinander vergleichen, da die Assets als Vektoren im mehrdimensionalen Raum dargestellt werden können.
Somit sind alle Dateien trotz ihrer unterschiedlichen Ausgangssituation dem gleichen mathematischen System untergeordnet, was sie beispielsweise über den euklidischen Abstand oder die Kosinus-Ähnlichkeit vergleichbar macht. Je näher sich die Assets im vektoriellen Raum sind, desto ähnlicher sind sie sich bezüglich ihrer semantischen Bedeutung.
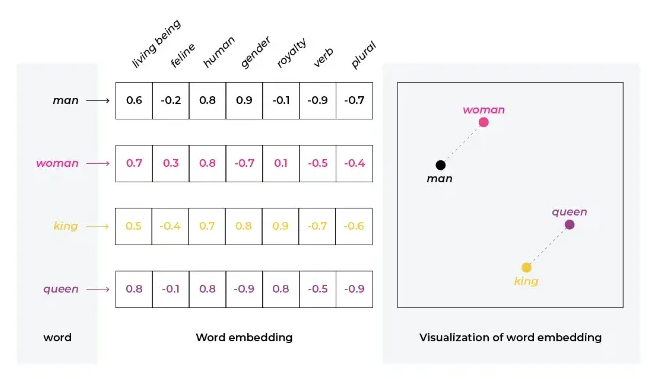
Vom LLM zum RAG-System
Als Basis für jedes RAG-System fungiert ein LLM. RAG-Systeme sind im Endeffekt nichts anderes als LLMs, deren standardmäßige Vektor-Datenbank um weitere Daten ergänzt wurde. Als Beispiel: Wenn mein RAG-System als Kochassistent fungieren soll, könnte man ein gutes Kochbuch als PDF in die Trainingsdaten integrieren. Frage ich das System nun nach Rezeptvorschlägen, wird bevorzugt ein Rezept aus dem in der Vektor-Datenbank hinterlegten Kochbuch geliefert.
Ein etwas komplexeres Beispiel wäre ein Onboarding-System für neue Mitarbeiter in einem Unternehmen. Man könnte hier diverse interne Unternehmensdokumente integrieren, die nicht in den üblichen Trainingsdatensätzen von LLMs enthalten sind. Über das RAG-System könnten diese Dokumente auf Basis eines Systemprompts aufbereitet und neuen Mitarbeitern, abhängig von ihrer Rolle, bereitgestellt werden.
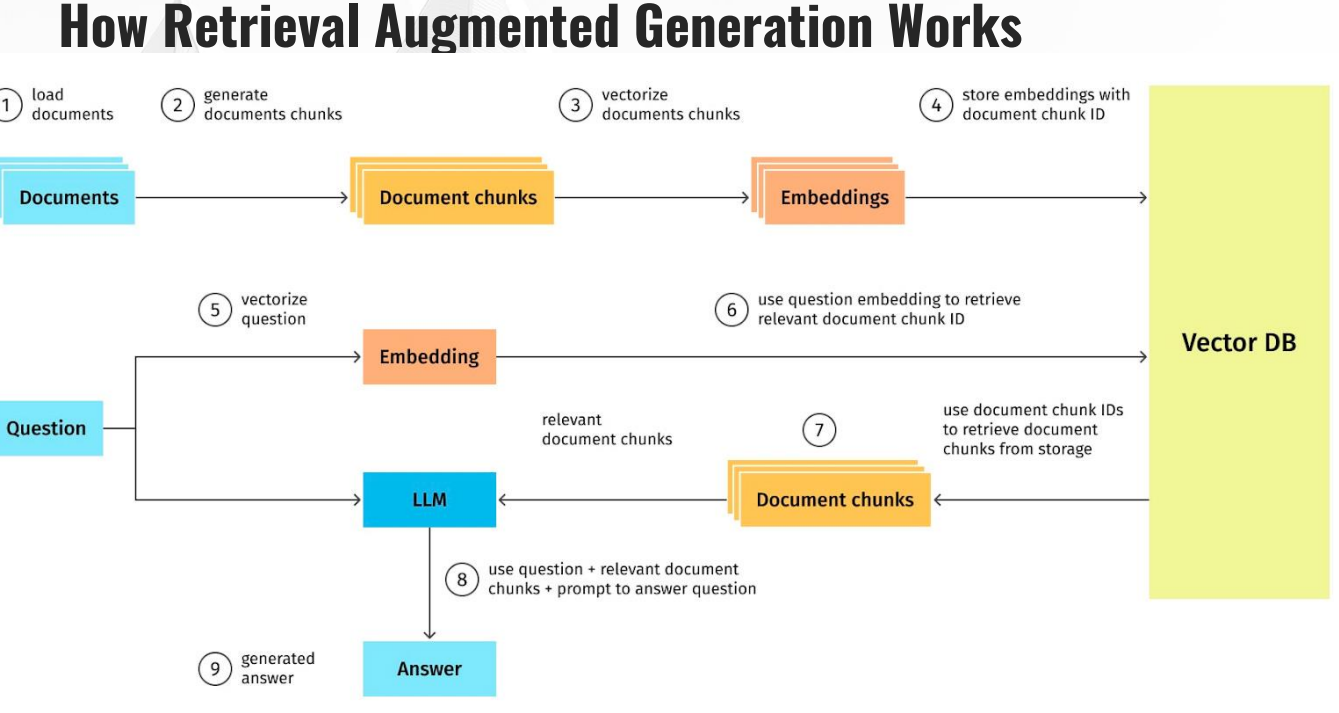
Etablierte Beispiele für RAG-Systeme sind Custom-GPTs, also konfigurierte Versionen von ChatGPT. Mit dieser Funktion erlaubt es OpenAI, dass man auf Basis des LLMs separate Vektor-Datenbanken anlegt und eine spezifische Aufgabe für den Assistenten definiert. So gibt es beispielsweise öffentliche Custom-GPTs, die beim Programmieren oder der Datenanalyse unterstützen.
RAG-Systeme entwickeln
Um ein RAG-System für die eigenen Zwecke zu entwickeln, sollte man zunächst den Use Case definieren. Wobei genau soll mich das System unterstützen?
Sobald der Use Case geklärt ist, sollte man sich auf ein Tool bzw. LLM festlegen. Die einfachste Variante wäre wohl ein Custom GPT; hier gibt es allerdings Bedenken bezüglich Datenschutz. Möchte man das RAG-System beispielsweise auf der eigenen Website öffentlich zugänglich machen, sollte das Tool DSGVO-konform sein. Hierfür wäre ein herkömmlicher Custom GPT nicht ausreichend. Als Workaround bieten sich KI-Plattformen wie Localmind an, welche die LLM-Software auf in Deutschland befindlichen Cloud-Servern hosten.
Im nächsten Schritt gilt es, die benötigten Trainingsdaten in einem passenden Dateiformat zu kompilieren und hochzuladen. Welche Assets genau benötigt werden, hängt vom jeweiligen Use Case ab.
Im vierten Schritt muss nun der Systemprompt erstellt werden. Hier wird definiert, welche Aufgaben der Assistent hat, wie er mit den Trainingsdaten und dem Input des Nutzers umgeht, welche Workflows bedient werden sollen etc. Der Systemprompt ist entscheidend für den Erfolg oder Misserfolg der Anwendung.
Letzter Schritt: Testing. Nachdem das RAG-System funktionsfähig ist, gilt es, den angepeilten Use Case in möglichst vielen verschiedenen Variationen von möglichst vielen verschiedenen Nutzern testen zu lassen. Früher oder später werden Unstimmigkeiten auftauchen, welche die Basis für eine erneute, sukzessive Anpassung des Systemprompts und der Trainingsdaten sind. Erst wenn nach mehreren Testläufen keine größeren Fehler mehr auftreten, ist das RAG-System fertiggestellt.
Anwendungsgebiete für RAG-Systeme
Das wohl relevanteste Anwendungsgebiet für RAG-Systeme ist die Content-Erstellung. Durch die Integration eines optimierten RAG-Systems in die Content-Erstellung lassen sich bestehende Workflows deutlich effizienter gestalten, bei gleichbleibender Qualität der Inhalte. Dabei kann das System nicht nur für komplette Fließtexte, sondern auch für einzelne Absätze oder SEO-Tags wie Meta-Titles und -Descriptions verwendet werden. Weiterhin können beispielsweise Briefings automatisch vertextet, bestehende Inhalte auf Lücken analysiert oder Abgleiche des eigenen Keyword-Sets mit dem der Konkurrenz durchgeführt werden. Dabei kann die große Schwäche von KI-Texten bezüglich Qualität, die immer gleiche Datengrundlage, durch eine personalisierte Vektor-Datenbank umgangen werden. Dieses Vorgehen hat allerdings den Nachteil, dass RAG-generierte Texte aufgrund der Halluzinationsprobleme von LLMs immer von Menschen auf Korrektheit gegengeprüft werden müssen. Selbst mit diesem zusätzlichen Schritt könnte der Zeitaufwand allerdings massiv reduziert werden.
Ein zweites Anwendungsgebiet stellen personalisierte KI-Chatbots dar. Diese können extern (beispielsweise auf der Firmen-Website) oder auch intern (beispielsweise zum Anlernen neuer Mitarbeiter) genutzt werden. Insbesondere für große Unternehmen sind Chatbots auf der eigenen Website schon länger Standard, da man hiermit Ressourcen sparen kann. Durch den Wechsel von traditioneller Chatbot-Technologie auf KI-Chatbots hat sich deren Qualität massiv gesteigert, und die Umsetzung wird auch für kleinere Unternehmen erschwinglich.
RAG-Systeme von seowerk
Sofern ihr Interesse an einem für euer Unternehmen zugeschnittenen RAG-System habt, tretet mit uns in Kontakt! Wir beraten euch gerne bezüglich Use Cases und setzen das RAG-System für euch um. Auch für andere Online-Marketing Leistungen stehen wir euch zur Verfügung.
Quellen
- Mike King: “The importance of Retrieval Augmented Generation (RAG)” (SMX Vortrag)
- https://www.computerweekly.com/de/definition/Large-Language-Model-LLM
- https://www.pixx.io/blog/was-weiss-chatgpt
- https://www.melibo.de/blog/gpt-4-revolutionare-features-und-signifikante-unterschiede-zu-gpt-3
- https://www.dotnetpro.de/backend/datenbanken/so-llms-vektordatenbanken-hocheffiziente-nlp-suchmaschinen-2903957.html
- https://medium.com/@EjiroOnose/vector-database-what-is-it-and-why-you-should-know-it-ae7e7dca82a4
- https://www.localmind.ai/
- https://openai.com/index/introducing-gpts/
- https://aws.amazon.com/de/what-is/vector-databases/
Interne Links
- LLMO: https://www.seowerk.de/news/llmo/
- Google AIO: https://www.seowerk.de/news/google-aio/
- SEO Agentur: https://www.seowerk.de/seo-agentur/
- Andere Leistungen: https://www.seowerk.de/leistungen/
In der modernen Medizin spielt die Kommunikation eine zentrale Rolle. Patient:innen erwarten schnelle, präzise Antworten und einfache Wege, um Termine zu vereinbaren oder Fragen zu klären. Hier kommen Medizin-Chatbots ins Spiel – digitale Assistenten, die durch den Einsatz von Künstlicher Intelligenz (KI) und maschinellem Lernen immer leistungsfähiger werden. In diesem Artikel möchten wir dir zeigen, wie Chatbots den Praxis- oder Klinikalltag erleichtern können und welche Möglichkeiten sich bieten.
Inhalt
- Wo wird KI in der Medizin eingesetzt?
- Was können Medizin-Chatbots?
- Welche Vorteile bieten Chatbots in der Medizin?
- Welche Maßnahmen sind wichtig für den Datenschutz?
- Wo liegen die Grenzen von Medizin-Chatbots?
- Jetzt Chatbot-Implementierung beauftragen!
Wo wird KI in der Medizin eingesetzt?
Neben der Nutzung von Chatbots für die Patientenkommunikation finden sich KI-Anwendungen in der Diagnostik, beispielsweise bei der Auswertung von Röntgenbildern oder der Analyse von Patientenakten zur Erkennung von Mustern und Auffälligkeiten. Darüber hinaus unterstützt KI bei der Medikamentenentwicklung, indem sie große Datenmengen analysiert und potenzielle Wirkstoffe identifiziert. Auch in der personalisierten Medizin spielt KI eine wichtige Rolle, indem sie Therapiepläne individuell auf Patient:innen zuschneidet.
Diese Arten von Chatbots gibt es im Gesundheitswesen:
- Informations-Chatbots beantworten häufig gestellte Fragen & bieten Bildungsressourcen.
- Diagnose-Chatbots sammeln Symptomdaten, analysieren sie und schlagen Diagnosen vor.
- Therapie- & Mental-Health-Chatbots unterstützen bei mentalen Gesundheitsproblemen durch kognitive Verhaltenstherapie und Achtsamkeitsübungen.
- Administrative Chatbots automatisieren Aufgaben wie Terminplanung und Abrechnung.

Was kann ein informativ-administrativer Medizin-Chatbot alles?
Terminvereinbarung durch den KI-Chatbot
Ein häufiger Einsatzbereich von Chatbots in der Medizin ist die Terminvereinbarung. Viele Praxen und Kliniken nutzen bereits erfolgreich Chatbots, um den Verwaltungsaufwand zu reduzieren. Der Vorteil: Mithilfe eines Medizin-Chatbots können sie die Anzahl der telefonisch vereinbarten Termine erheblich reduzieren. Patient:innen schätzen wiederum die Möglichkeit, rund um die Uhr Termine buchen zu können, ohne in der Warteschleife zu hängen. Auch Studien haben gezeigt, dass Chatbots in der Lage sind, administrative Aufgaben wie Terminvereinbarungen effizient zu übernehmen, was die Arbeitslast des Personals erheblich reduzieren kann.1
Nach einem Arztbesuch kann der Chatbot Follow-up-Nachrichten senden, um die Zufriedenheit der Patient:innen zu erfragen, zum Bewerten aufzurufen oder weitere Anweisungen zu geben. Alle Aktivitäten des Chatbots sind jedoch nur mit Einwilligung der jeweiligen Person möglich.
KI beantwortet Patientenfragen
Ein weiterer großer Vorteil von Chatbots ist die Entlastung des Praxispersonals durch die Beantwortung häufiger Patientenfragen. Themen wie Sprechzeiten, Anfahrt oder einfache medizinische Auskünfte lassen sich schnell und effizient durch einen gut programmierten Chatbot abdecken. Er ist in der Lage, routinemäßige Fragen effektiv zu beantworten und dabei eine hohe Zufriedenheit bei den Patient:innen zu erzielen. So bleibt dem Team mehr Zeit für die persönliche Betreuung der Patient:innen vor Ort.
Erinnerung an Vorsorgeuntersuchungen & Medikamente durch Chatbots
Darüber hinaus können Chatbots Patient:innen an Vorsorgeuntersuchungen erinnern. Sie senden automatisierte Nachrichten, um auf bevorstehende Termine oder wichtige Gesundheitschecks hinzuweisen. Dies erhöht die Chance, dass Patient:innen rechtzeitig zu ihren Untersuchungen erscheinen. Ein Chatbot kann Patient:innen zudem an die Einnahme ihrer Medikamente erinnern und ihnen Informationen über die Dosierung und mögliche Nebenwirkungen bereitstellen. Laut einer Meta-Analyse von Studien zu Chatbots im Gesundheitswesen haben die digitalen Helfer positive Effekte auf die Compliance und das allgemeine Wohlbefinden der Patient:innen.2
Verwaltung von medizinischen Fragebögen mit KI
Chatbots können auch dazu genutzt werden, medizinische Fragebögen zu verwalten. Patient:innen geben vor ihrem Termin relevante Informationen ein, die der Arzt/die Ärztin später nutzen kann, um den Besuch effizienter zu gestalten. Dies spart Zeit und sorgt für einen reibungsloseren Ablauf in der Praxis oder Klinik. Eine systematische Überprüfung hat gezeigt, dass Chatbots effektiv bei der Verwaltung und Verarbeitung von Patientendaten sind, was zu einer effizienteren Praxisführung beiträgt.1
Chatbots: Unterstützung bei der Vorbereitung auf Untersuchungen
Medizin-Chatbots können Patient:innen Schritt für Schritt durch die Vorbereitung auf bestimmte Untersuchungen führen. Dies kann besonders bei komplexeren Verfahren hilfreich sein. In diesen Fällen müssen Patient:innen oft bestimmte Anweisungen befolgen, wie zum Beispiel Nüchternheit vor einer Blutuntersuchung oder spezielle Ernährungsweisen vor einer Koloskopie. Studien haben gezeigt, dass Chatbots hierbei hilfreich sein können, indem sie klare und verständliche Anweisungen geben und so zur Reduzierung von Fehlern beitragen.1

Chatbots: Vorteile für das medizinische Personal
Medizin-Chatbots können das Praxis- und Klinikpersonal deutlich von Routineaufgaben entlasten und so die Arbeitszufriedenheit erhöhen. Bots bieten Antworten auf häufig gestellte Fragen, verwalten Termine und unterstützen bei administrativen Aufgaben, wodurch das medizinische Personal mehr Zeit für die direkte Patientenbetreuung hat.
Durch die personalisierte Kommunikation, die rund um die Uhr und teilweise in mehreren Sprachen möglich ist, finden Patient:innen zudem immer eine Ansprache und fühlen sich auch auf der Praxis- oder Klinikwebsite gut betreut.
Skalierbarkeit von Chatbots in der Medizin
KI-Chatbots sind skalierbar. Das heißt, bei steigenden Patientenzahlen muss kein zusätzliches Personal eingestellt werden, um die standardisierte Kommunikation zu stemmen. Vor allem in Zeiten des Fachkräftemangels kann das ein entscheidendes Argument für Chatbots in der Medizin sein.
Langfristige Kostenersparnis dank KI im Gesundheitswesen
Die – vergleichsweise kostengünstige – Implementierung von Chatbots kann langfristig zu erheblichen Kosteneinsparungen führen. Durch die Automatisierung von Routineaufgaben werden Personalressourcen effizienter genutzt, und die Fehlerquote kann reduziert werden. Dies zeigt sich auch darin, dass Patient:innen besser betreut werden und die Praxis oder das Klinikum zufriedener verlassen. Studien belegen, dass die Investition in Chatbots finanziell vorteilhaft ist und langfristig zur Optimierung der Praxisführung beiträgt.1
Datenschutz & Sicherheit beim Einsatz von Medizin-Chatbots
Ein wichtiger Punkt bei der Implementierung von Chatbots in der Medizin sind der Datenschutz und die Sicherheit der Patientendaten. Dazu gehört die Einhaltung von Vorschriften wie der Datenschutz-Grundverordnung (DSGVO).
So müssen Patient:innen explizit zustimmen, dass ihre Daten vom Chatbot verarbeitet werden dürfen – sie können auch deren Löschung verlangen. Personen haben ein Recht darauf zu erfahren, welche Daten gesammelt wurden und wie lange diese gespeichert werden. Dabei dürfen nur notwendige Daten verarbeitet werden.
Wichtige Sicherheitsmaßnahmen für Medizin-Chatbots sind:
- Verschlüsselung: Alle Datenübertragungen müssen stark verschlüsselt sein, um Missbrauch zu verhindern.
- Zugriffskontrollen: Nur autorisiertes Personal darf auf Daten zugreifen, unterstützt durch starke Authentifizierungsmechanismen.
- Datenanonymisierung: Sensible Daten sollten anonymisiert werden, um die Privatsphäre der Patient:innen zu schützen.
- Protokollierung: Um verdächtige Aktivitäten zu erkennen, sind umfassende Protokollierungs- und Überwachungsmaßnahmen notwendig.
- Regelmäßige Sicherheitsüberprüfungen: Sicherheitsmaßnahmen sollten regelmäßig überprüft und aktualisiert werden.
Die nahtlose Integration in bestehende Systeme wie elektronische Patientenakten (EPA) ist entscheidend, um die Effizienz und Sicherheit zu gewährleisten.

Kritische Einordnung: Grenzen der Chatbots in der Gesundheitskommunikation
Natürlich haben Chatbots auch ihre Grenzen. Besonders im Bereich der Diagnosestellung ist Vorsicht geboten. Chatbots dürfen keinesfalls die professionelle medizinische Beratung ersetzen. Sie können jedoch unterstützend wirken, indem sie zum Beispiel Vorabinformationen sammeln oder Patient:innen darauf hinweisen, wann ein Arztbesuch notwendig ist.
Studien zur Genauigkeit von Chatbots in spezifischen medizinischen Bereichen haben gezeigt, dass die Technologie teilweise noch verbesserungswürdig ist.3 Chatbots dürfen keine Fehlinformationen vermitteln und müssen für alle User verständlich sein, um Missverständnisse zu vermeiden. Zudem muss auf den Schutz der Daten geachtet werden.
Trotzdem können Chatbots heute schon einiges: Sie sind mit fortschrittlichen KI-Funktionen und Daten ausgestattet, um komplexe Fragen zu verstehen, einen personalisierten, natürlichen Dialog zu führen und zunehmend anspruchsvollere Aufgaben zu übernehmen. Dementsprechend sieht die Zukunft der Chatbots im Gesundheitswesen durchaus vielversprechend aus.
Dein Partner für Gesundheitskommunikation: erfolgreiche Chatbot-Implementierung durch Expert:innen
Unsere Online-Marketing-Agentur unterstützt Kliniken und Arztpraxen dabei, innovative Kommunikationslösungen zu finden und umzusetzen. Wir bieten umfassende Dienstleistungen an, um deine Praxis oder Klinik optimal im digitalen Raum zu positionieren. Von SEO und SEA über Webentwicklung bis hin zu Grafik, Social Media Management und Content-Erstellung sind wir dein Partner für alle Belange der Gesundheitskommunikation. Unsere Erfolge sprechen für sich: Zahlreiche zufriedene Kund:innen aus dem Gesundheitswesen profitieren bereits von unseren maßgeschneiderten Lösungen.
Wenn du mehr über unsere Leistungen als Agentur für Klinikmarketing und Praxismarketing erfahren möchtest, klicke auf die Links oder kontaktiere uns direkt. Lass uns gemeinsam die digitale Zukunft deines Unternehmens gestalten.
Quellen:
1https://link.springer.com/article/10.1007/s10209-024-01118-x
2https://www.mdpi.com/2227-9032/12/5/534
4https://relevant.software/blog/chatbots-in-healthcare/
Wie KI die Google-Rankings verändert – und wie Sie im Spiel bleiben
Unter AI Overviews (AIO, vorher Search Generative Experience (SGE)) bezeichnet Google die geplante Überarbeitung der organischen Suche in Form von generativen KI-Snapshots, welche oberhalb der organischen Suchergebnisse ausgespielt werden sollen. Mithilfe dieser KI-Snapshots, welche sich inhaltlich auf die jeweilige Suchintention anpassen, verspricht sich Google eine höhere Nutzerzufriedenheit.
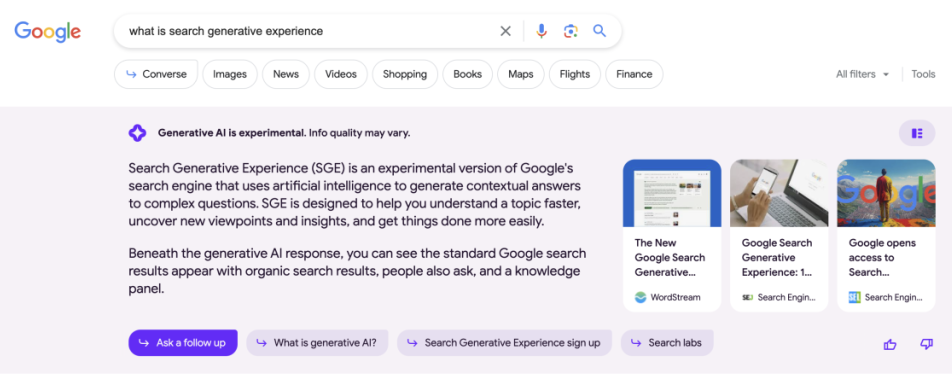
Vor gut einem Jahr bei der Google I/O 23 Innovationskonferenz als Reaktion auf KI-Chatbots wie Chat-GPT angekündigt, steht AIO Gerüchten zufolge kurz vor der Veröffentlichung für die breite Masse am 14. Mai 2024. Für SEOs und Unternehmer, welche die Google-Suche als wichtigen Traffic-Kanal nutzen, könnte sich hiermit einiges ändern. Wie genau die AIO KI-Snapshots aussehen, wie sich das neue Element auf die organische Suche auswirken könnte und wie man sich schon jetzt auf den Rollout vorbereiten kann, stellen wir im Folgenden vor.
AI Overviews – Darstellung in der Praxis
Wie oft werden sie ausgespielt?
Google’s AIOs werden, laut einem Test von Authoritas vom März 2024, für gut 91% der Suchanfragen ausgespielt. Die Wahrscheinlichkeit schwankt dabei je nach Branche relativ stark, so sind Nischen wie Versicherungen (52%) und Finanzen (71%) seltener betroffen.
Wie sehen die KI-Snapshots aus?
Die KI-Snapshots können je nach Suchintention des Begriffes relativ unterschiedlich aussehen. Für Suchbegriffe mit einer Kaufintention werden bspw. Informationen aus Online-Shops ausgespielt und Produktvergleiche angeboten:
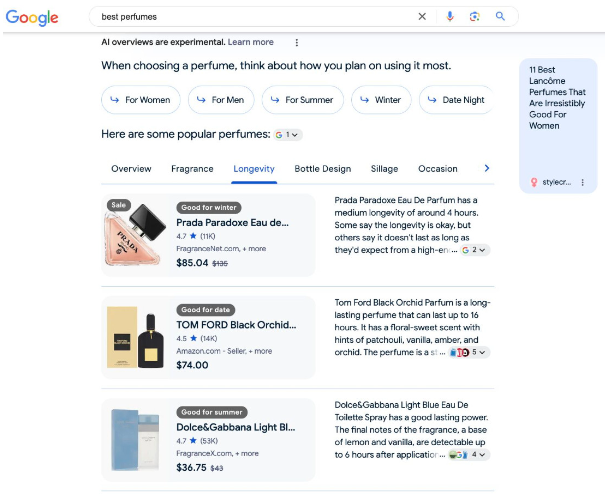
Für eher informationelle Suchanfragen wie „Was ist generative Suche“ werden inhaltliche Zusammenfassungen mit Quellen und Folgefragen aufbereitet:
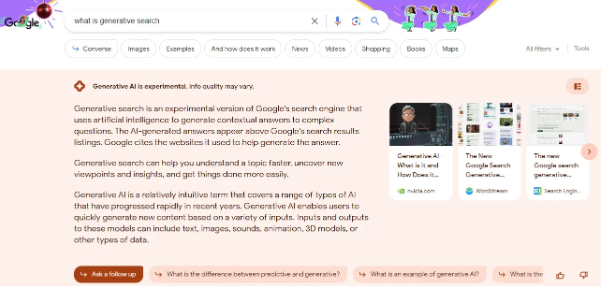
Die Quellen der Ressourcen, auf welche sich AIOs beziehen, werden teilweise im Text oder unterhalb vom KI-Snapshot dargestellt. Die Traffic-Weitergabe findet also nur noch über das Verlinken der Quellen statt, anstatt die Websites wie aktuell als Hauptmedium der Suchergebnisseite zu platzieren.
Welche Funktionen bieten AIOs?Neben einer Optimierung der Suchmaschinenfunktion bietet AIO noch weitere Anwendungsbereiche, die man von generativer KI wie Chat-GPT oder Google Gemini bereits kennt. Dazu gehören:
- Textgeneration: AIO kann vollständige Texte nach inhaltlichen Vorgaben erstellen und den Stil anpassen. Das Ergebnis kann man sofort in ein Google Doc oder in Google Mail exportieren.
- Bildgeneration: AIO bietet die Möglichkeit, via Text-to-Image Bilder nach den eigenen Wünschen zu generieren.
- Conversational-Mode: Sofern man bereits mit einem KI-Snapshot interagiert hat, kann man dort direkt Folgefragen stellen, welche in einer Art Konversation vom Chatbot beantwortet werden.
- etc.
Wie erfolgt der Zugriff auf AIO?
Um aktuell Zugriff auf Google's AI Overviews zu haben, muss man über einen VPN einen Zugriff über bspw. die USA simulieren. Für Deutschland ist die Beta-Version noch nicht freigegeben, höchstwahrscheinlich aufgrund von Compliance Problemen mit dem Digital Markets Act (DMA) der Europäischen Union.
Technische Grundlage von Google's AIO
Wie auch Google’s KI-Chatbot, Google Gemini, basiert AIO auf Google’s Large Language Model (LLM) PaLM 2. Kurz zusammengefasst: ein Large Language Model ist ein generatives Sprachmodell, welches mit riesigen Datenmengen gefüttert wird. Je mehr dieser sog. Trainingsdaten einem Modell zugeführt werden, desto präziser kann es auf Anfragen reagieren und entsprechende Antworten liefern. Google AIO nutzt in diesem Fall als Datengrundlage den Google Index und arbeitet die dort vorhandenen Informationen sinnvoll für den Nutzer auf. Weitere Informationen zum Thema LLMs und wie man diese gewinnbringend für die Neukunden-Gewinnung Nutzen kann, haben wir in unserem Large Language Model Optimization (LLMO) Artikel zusammengefasst.
Bedeutung von AIO für organischen Traffic
Wichtig: In der von Authoritas getesteten Version der AIOs wurde der KI-Snapshot erst nach Klick auf einen Link oder Button dargestellt. Nutzer müssen also aktiv mit dem Feature interagieren, um organische Ergebnisse zu verdrängen.
Im weiter oben bereits referenzierten Test von Authoritas wurde neben der prozentualen Anzahl von AIO-Ergebnissen auch die Auswirkung auf die organischen Ergebnisse gemessen. Da die KI-Snapshots oberhalb des ersten organischen Ergebnisses platziert sind, werden diese aktuell entsprechend nach unten verschoben. Im Durchschnitt beträgt die Distanz auf der Y-Achse dabei ca. 1250 Pixel. Aufgeschlüsselt nach verschiedenen Suchanfragen sieht die Verschiebung wie folgt aus:
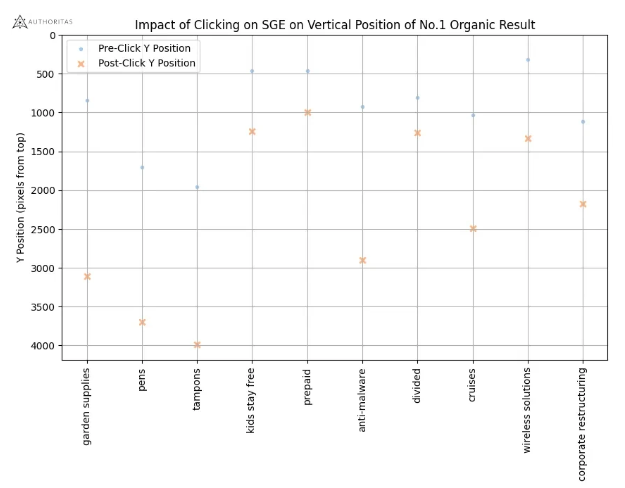
Als Referenz: Der initial sichtbare Bereich der Google Ergebnisse misst in der Desktop Version in einer Standard-Auflösung von 1920 x 1080 px ca. 920 Pixel. Das bedeutet, dass das erste organische Ergebnis im Schnitt vollständig aus dem initialen Sichtbereich verschwinden wird. Wie genau sich eine solche Verschiebung auf die Klickraten der organischen Ergebnisse auswirken wird, müsste man nach dem globalen Rollout anhand der Live-Daten analysieren. Allgemein kann man aber sagen: Je tiefer ein Nutzer scrollen muss, desto geringer ist die Wahrscheinlichkeit, dass ein Ergebnis gesehen, geschweige denn geklickt wird. Als Referenz dazu die durchschnittliche Klickrate der Google Suchergebnisse auf Basis der Pixel-Position:
Fest steht also: Sofern AI Overviews wie hier beschrieben umgesetzt werden, werden organische Ergebnisse höchstwahrscheinlich wesentlich seltener geklickt.
Wie kann man in AIO KI-Snapshots erscheinen?
Nachdem nun geklärt wurde, dass der Rollout von AIO mit hoher Wahrscheinlichkeit zu einer negativen Auswirkung bzgl. organischem Traffic führen wird, bleibt die Frage: Wie kann man im KI-Snapshot mit der eigenen Website erscheinen? Und wie kann man die eigene Website bereits heute auf den Rollout von AI Overviews vorbereiten? Schließlich sollten Ergebnisse, welche im KI-Snapshot aufgeführt sind, entsprechend oft geklickt werden.
Es gibt von Google keine offizielle Dokumentation zu diesem Thema, allerdings gibt es einige Rückschlüsse, die man aus der Funktionsweise des normalen Google Ranking-Algorithmus, Äußerungen von Google-Mitarbeitern und der Funktionsweise von Large Language Models ziehen kann. Folgende Maßnahmen würden sich unserer Meinung nach für Website-Betreiber anbieten:
1. Status-Quo Analyse
Zu Beginn der Betrachtung von AI Overviews bezogen auf die eigene Performance sollte immer eine Analyse der Live-Umgebung bei Google stehen. Erstens kann man hiermit sicherstellen, dass überhaupt ein KI-Snapshot ausgespielt wird, zweitens kann man hiermit prüfen, wie der etwaige KI-Snapshot genau aussieht. Nur auf Basis dieser Erkenntnisse können nächste Schritte eingeleitet werden.
2. EEAT Optimierung
EEAT steht für Expertise, Experience, Authoritativeness und Trustworthiness. Das Konzept wurde von Google als Leitlinie für menschliche Qualitätstester der Suchergebnisse (Quality Rater) eingeführt und soll sicherstellen, dass von Google ausgespielte Ergebnisse deren Ansprüchen bzgl. Vertrauen und Autorität gerecht werden. Zur Optimierung von EEAT gibt es mehrere Maßnahmen, bspw.:- Transparente Informationen zum Website-Betreiber über das Impressum
- Verlinken von Autoren der Inhalte inkl. Autoren-Profil
- Transparente Informationen zum Website-Betreiber über das Impressum
- Aktualität der Inhalte
- Gesamtqualität der Inhalte (Helpful Content)
- Topical Authority
- etc.
3. Content Strategie mit Fokus auf Entitäten und Longtails
Das Suchverhalten wird sich durch Google’s AI Overviews höchstwahrscheinlich insofern ändern, dass Nutzer stärker in die Spezialisierung der Suchanfragen durch Longtails oder “natürliche” Formulierungen gehen, anstatt sich auf kürzere Hauptkeywords zu fokussieren. Dieser Effekt wird durch den Konversationsmodus von AIO noch weiter verstärkt, sodass Nischeninhalte relevanter werden.
Entsprechend sollte die eigene Content-Strategie weniger in Richtung ein Keyword pro Seite und eher in die Richtung ganzheitlicher Content bzw. Abhandeln von Entitäten gehen, welche ein Thema möglichst ausführlich durchleuchten. Je tiefer ein Thema auf einer Seite behandelt wird, desto mehr spezialisierte Informationen kann Google via AIO extrahieren und für Nutzer bereitstellen.
4. Markenbekanntheit im Web steigern
Da Google’s AI Overviews auf einem Large Language Model (LLM) basieren, kann man die Relevanz durch Nennungen in anderen Quellen steigern. Nur wenn das LLM in den Trainingsdaten, darunter die Suchergebnisse von Google, oft auf die eigene Marke, Produkte oder Dienstleistungen im korrekten Kontext stößt, kann eine Relevanz für wichtige Suchanfragen entstehen.
Für den Aufbau solcher “Kookkurenzen” bieten sich eine Vielzahl an Maßnahmen an, bspw. Placements bei großen Publishern, strukturierte PR-Arbeit, Fokus auf redaktionellen Content (Stichwort: Content mit Mehrwert), etc.
5. Pflege von Profilen auf Aggregatoren, Foren und Wikipedia
Aggregatoren wie booking.com oder Idealo sind aufgrund ihrer hohen Sichtbarkeit und Autorität in der Suche oft in KI-Snapshots vertreten. Je nach Nische gibt es unterschiedliche Aggregatoren, welche die eigenen Services oder Produkte aufführen. Sofern möglich, sollte man die dort hinterlegten Informationen pflegen und aktuell halten, sodass Nutzer über diesen Umweg problemlos auf die eigene Website oder zu den eigenen Produkten/Dienstleistungen finden können.
Weiterhin wurde im Versuch von Authoritas festgestellt, dass die Frage und Antwort Plattform “Quora” unverhältnismäßig oft in den KI-Snapshots auftaucht. Durch clevere Einflussnahme relevanter Threads auf solchen Plattformen könnte man die eigene Marke oder Produkte über Drittanbieter in KI-Snapshots einschleusen. Neben Quora würde sich weiterhin Reddit anbieten, eine Social-News-Plattform, welche aktuell ein noch nie dagewesenes Wachstum bzgl. Google Rankings erlebt und vor Kurzem einen Deal mit Google bzgl. der Bereitstellung von Daten zum Trainieren von LLMs abgeschlossen hat.
Als dritte dominante Entität in AIO gibt es noch Wikipedia, die Einflussnahme auf relevante Unterseiten ist allerdings schwierig bis unmöglich.
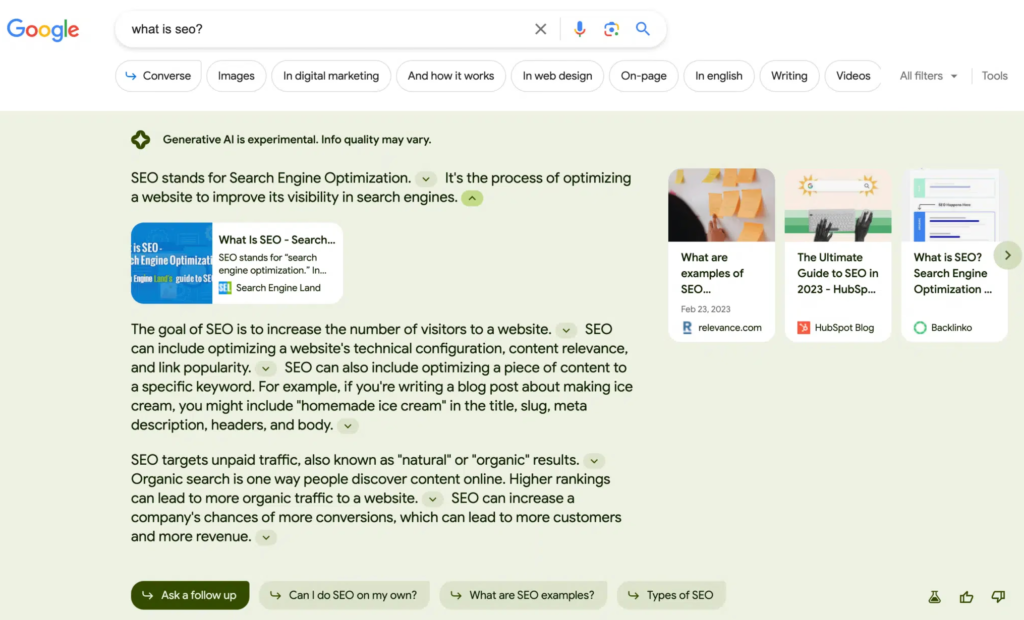
6. Traditionelles SEO
Laut der Studie von Authoritas befinden sich ca. 20% der Links in AI Overview Snapshots in den Top 10 der organischen Rankings. Unabhängig davon, dass normale, organische Rankings auch nach Go-Live von AIO weiterhin relevant bleiben, ist die Chance für Seiten mit Top-Rankings also doppelt so hoch im KI-Snapshot aufzutauchen, wie für andere Seiten. Entsprechend bleiben bewährte SEO-Maßnahmen wie UX-Optimierung, inhaltliche Optimierung oder technische Optimierung weiterhin relevant.
Jetzt Kontakt aufnehmen und kostenlose SEO-Erstberatung erhalten!Unabhängig von der organischen Performance gibt es darüber hinaus eine Wechselwirkung mit bekannten SEO-Maßnahmen, da nur indexierbare und performante Ergebnisse überhaupt für Google's AIOs infrage kommen. Entsprechend ist die Basis für ein Auftauchen im KI-Snapshot eine saubere, technische Grundlage bzgl. Crawlbarkeit, Indexierbarkeit und Pagespeed bzw. Core-Web-Vitals.
Schlussbetrachtung
Abschließend kann man sagen, dass das Release von Google’s AIO mit hoher Wahrscheinlichkeit ein einschneidendes Erlebnis für alle Publisher und Plattformen wird. Das Suchverhalten der Nutzer könnte sich langfristig ändern und es bleibt ungewiss, wie genau die Milliarden an Suchanfragen bei Google zukünftig aufgeteilt werden.
Kritisch betrachtet muss sich Google auch die Frage gefallen lassen, ob diese Verarbeitung von fremden Inhalten auf der Suchergebnisseite in Form der KI-Snapshots keine übergriffige Handlung gegenüber den Publishern ist. Sogenannte Zero Click Searches könnten durch ausführliche AI Overview Resultate deutlich zunehmen. Die ewige Symbiose zwischen Google, welches auf den Zugriff auf Inhalte im Web angewiesen ist, und Publishern, welche durch Google Services Traffic erhalten, könnte für Publisher zu einseitig werden. Bereits jetzt sperren einige große Plattformen wie die New York Times Crawler von AI-Tools wie den GPT-Bot von Open AI oder den GoogleExtended-Bot, welcher Daten zur Verbesserung von Google’s generativen AI-Lösungen wie Gemini sammelt. Je nach Auswirkung von AIO auf die Traffic-Zahlen könnte der Rollout zumindest theoretisch ein Aufbäumen der großen Publisher nach sich ziehen.
Wenn Sie sich schon heute auf den Go-Live der AI Overviews vorbereiten wollen, fragen Sie gerne bei uns an! Wir unterstützen Sie bei der Status-Quo Analyse, geben fachmännische Vorschläge für frühe Optimierungsansätze und stehen Rede und Antwort bei Fragen zum Thema AIO, LLMO und SEO.
Quellen
- https://www.authoritas.com/blog/research-study-the-impact-of-google-sge-on-brands
- https://www.authoritas.com/blog/research-study-the-impact-of-googles-search-generative-experience-on-rankings
- https://www.red66marketing.com/blog/google-search-generative-experience-explained/
- https://blog.google/products/search/generative-ai-search/
- https://www.evergreenmedia.at/ratgeber/ki-seo/search-generative-experience/
- https://www.seokratie.de/google-sge/
YouTube-Kanal optimieren? Geht das?
Auf YouTube erfolgreich sein, heißt nicht nur gefunden werden, sondern auch mit Content überzeugen. Wir haben die wichtigsten Punkte der ersten Seminarsitzungen zusammengefasst:
1. YouTube lebt von Regelmäßigkeit
Auf YouTube reicht es nicht, alle paar Monate ein neues Video auf dem eigenen Kanal zu veröffentlichen. Wer auf YouTube organisch erfolgreich werden will, braucht den regelmäßigen Kontakt zur Zielgruppe. Ansonsten sollte man auf bezahlte Werbeanzeigen setzen.
Hier gilt: Mindestens ein Video pro Woche – am besten immer zur selben Uhrzeit!
2. YouTube braucht plattformspezifische Inhalte
Videomaterial, das für Plattformen wie Facebook und Instagram erstellt wurde, sollte nicht in gleicher Form auf YouTube geteilt werden. YouTube-Videos werden vorrangig mit Ton abgespielt, besitzen ein anderes Format und haben eine gewisse Länge. Gut funktionieren u. a. Tutorials, How-To-Anleitungen, Life Hacks, Reviews, Top 10 Ratings und Pranks.
Hier gilt: Inhalte speziell für YouTube kreieren!
3. YouTube Mix aus Hub-, Hero- und Help-Content
Auf YouTube sollte man nicht darauf hoffen, mit einem einzigen Video einen viralen Hit zu landen. Der richtige Mix aus Hub-Content (serielle, unterhaltende Inhalte), Hero-Content (Highlight-Inhalte mit einer großen Reichweite) und Help-Content (Basis-Inhalte über das Produkt und/oder Dienstleistung) ist entscheidend. Rein informative Formate laden die Brand nicht emotional auf. Rein unterhaltsame Formate bringen Reichweite, aber kaum Business.
Hier gilt: Nicht ein großer Hit, sondern vielseitiger Content!
4. YouTube-Inhalte leben lange
YouTube-Content hält sich. Auch Videos, die älter als 30 Tage sind, können jahrelang Klicks bringen. Bei der Produktion von YouTube-Videos sollte man sich daher genau überlegen, was veröffentlicht wird.
Hier gilt: Inhalte sollten langfristig relevant sein!
5. YouTube-Videos teilbar machen
Teilbarkeit von YouTube-Videos lässt eine größere Zielgruppe erreichen und Videos viral gehen. Um diese zu erhöhen, kann man auf bestimmte Trends aufsteigen, die im Internet Relevanz haben oder Werte vermitteln, die von der Zielgruppe geteilt werden. Auch Videos, die eine starke emotionale Reaktion auslösen, werden eher verbreitet.
Hier gilt: Je mehr Trend, Wert und Emotion, desto größer die Teilbarkeit!

6. YouTube braucht Suchmaschinenoptimierung
YouTube ist nicht nur das zweitgrößte soziale Netzwerk (hinter Facebook), sondern gehört zum Google-Imperium. Die Suchmaschine ist mit 91,6 Prozent Marktanteilen weltweit der Platzhirsch unter den Suchmaschinen. Nicht umsonst kommt viel Traffic über die Suchleiste von Google.
Hier gilt: Ohne SEO / Suchmaschinenoptimierung wird ein YouTube Kanal nicht erfolgreich!
7. YouTube-Nutzer müssen nicht eingekauft werden
Nutzer auf YouTube schauen fast nur organische Beiträge, d. h. YouTube-Nutzer suchen gezielt nach Inhalten und schauen diese freiwillig bis zum Ende an. Der YouTube-Algorithmus sollte daher richtig genutzt werden, um organische Reichweite aufzubauen.
Hier gilt: Organisch first, Paid second!
8. YouTube setzt auf Community-Management
Die YouTube-Community ist der wichtigste Teil des YouTube-Kosmos. Ohne Interaktion mit der Zielgruppe gerät ein YouTube-Kanal schnell in Vergessenheit. Eine direkte Ansprache der Zuschauer und der direkte Blick in die Kamera erhöhen die Zuschauerbindung und fördern einen Dialog auf Augenhöhe.
Hier gilt: Interaktion mit der Community, auch über den Community-Tab!
Sie möchten mehr Informationen zum Thema YouTube-Optimierung? Melden Sie sich bei unseren Experten unserer YouTube SEO Agentur. Wir beraten Sie gerne zu Ihrem konkreten Projekt oder vermitteln unsere Expertise einer themenspezifischen Schulung.
Was ist neu an den Facebook und Instagram Shops?
Die Facebook Shops können individuell konfiguriert und personalisiert werden. In wenig Schritten können Unternehmer somit ihren persönlichen Online Shop bauen – mit eigenen Bildern, Texten, Kategorien und Farben. Dieser ist dann für Kunden über Facebook und Instagram erreichbar, wo sie alle Funktionen nutzen können, ohne auf eine externe Webseite geleitet zu werden.

Auch auf Instagram tut sich einiges: Da immer mehr Unternehmer Live-Videos nutzen, um mit ihrer Community zu interagieren und beispielsweise neue Produkte vorzustellen, reagiert Instagram und integriert die Shopping-Funktion nun auch endlich in Live-Streams. Zukünftig können Unternehmer ihre Produkte also nicht nur in Beiträgen und Stories markieren, sondern auch in Live-Videos. Der große Vorteil: User können die Produkte anschauen, ohne damit das Live-Video zu verlassen.

Doch nicht nur auf den Plattformen selbst gibt es Neuigkeiten. Auch der Commerce Manager im Business Manager wird komplett überarbeitet. Was sich hier alles genau tut, wird sich zeigen, wenn Facebook die neuen Funktionen für alle Marketer zur Verfügung stellt.
eCommerce mit Facebook: Wohin soll die Reise gehen?
Die große Vision von Facebook ist eine Verknüpfung seiner verschiedenen Dienste. Damit soll neben Facebook und Instagram auch WhatsApp über den gleichen Funktionsumfang verfügen und mit den anderen Plattformen integriert werden. Sprich wer künftig etwas über Instagram kauft, kann mit der Kreditkarte, die ggf. in FB hinterlegt ist bezahlen und Updates zur Bestellung via WhatsApp erhalten.
Für eine einzigartige User-Experience setzt Facebook auf AR (Augmented Reality). Dadurch könnte die neue Sonnenbrille oder das neue T-Shirt virtuell anprobiert oder der neue Couchtisch virtuell neben das eigene Sofa Zuhause gestellt werden.
Die Funktionen sollen für Unternehmer kostenlos bleiben. Facebook erwartet sich aber durch den Ausbau seiner E-Commerce Tools einen enormen Anstieg der Werbeeinnahmen. Experten sehen den Social-Media-Riesen mit seinen 2,6 Milliarden Nutzern als ernstzunehmende Konkurrenz für Größen wie Etsy, Ebay oder sogar Amazon.

Fragen zu integrierten Shops auf Facebook oder Instagram? Unsere Experten für Social Media Marketing helfen weiter und beraten zum optimalen Set-up des eigenen Social Media Stores.
Gezieltes Targeting durch die Verbindung von Search und YouTube
Werbetreibende stehen oft vor der Herausforderung die richtigen Zielgruppen zu erreichen. Oftmals wird sehr viel Werbebudget ausgegeben, ohne die gewünschten Umsätze zu erzielen.
Vielleicht standen Sie selbst schon vor der Tatsache, dass Ihre Google Ads Suchnetzwerk-Anzeigen häufig ausgespielt werden, diese aber eine schlechte Klickrate aufweisen. Eigentlich suchen viele Nutzer nach Ihrem Produkt oder Ihrer Dienstleistung, sie klicken aber meist auf einen Wettbewerber, den sie bereits kennen.
Die folgende Grafik beschreibt das Problem: Im ersten blauen Balken ist die Vielzahl an Suchanfragen für ein Produkt oder eine Dienstleistung ersichtlich. Ihre Anzeigen werden demnach häufig eingeblendet, wenn Nutzer genau nach Ihren Keywords suchen. Da Sie aber bspw. häufig nicht an der obersten Position sichtbar sind, klickt der Großteil der Nutzer nicht auf Ihre Webseite, der Anteil der Webseitenbesucher ist sehr gering (geringe CTR = Klickrate). Der Anteil derjenigen, die letzten Endes auf Ihrer Webseite einen Kauf durchführen oder Kontakt mit Ihnen aufnehmen ist dann noch geringer, was Sie am dünnen blauen Balken rechts erkennen können. Schlussendlich gäbe es viele potentielle Kunden, von denen aber nur ein Bruchteil den Weg auf Ihre Webseite schafft und konvertiert.

Wie können Sie also mehr Nutzer auf Ihre Webseite bringen, die genau an Ihrem Produkt oder Ihrer Dienstleistung interessiert sind? Gerade im Online Marketing gibt es durch gezieltes Targeting immer bessere Ausrichtungsmöglichkeiten. Vor allem die Erstellung von Zielgruppen wurde in Google Ads in den letzten Jahren ausgebaut. Wer sich die Datenmengen von Google für die eigene Werbestrategie zu Nutze macht, ist klar im Vorteil. Aber wie setzt man das in YouTube um? Mit einer Ausrichtung, welche die Daten aus der Google Suche verwendet.
YouTube for Action – mit Custom Intent Audiences
Global gesehen werden Videos bereits 2021 insgesamt 82% des Konsum-Traffics ausmachen. Auch YouTube wird als Werbeplattform immer wichtiger, denn mehr als 55% der Internetnutzer suchen auf Google nach einem Produkt und möchten im Anschluss in Videos mehr darüber erfahren, bevor sie es kaufen. Genau diese Nutzer, die bereits in Google nach Ihrem Produkt gesucht haben, können Sie mit Custom Intent Audiences in YouTube erreichen.
Diese Ausrichtung ermöglicht es Nutzer anzusprechen, die in den letzten sieben Tagen nach Ihrem Produkt gesucht haben. Diesen wird beim nächsten Besuch auf YouTube Ihre Werbeanzeige ausgespielt – Sie erreichen genau die Menschen, die aktuell an Ihrem Produkt interessiert sind und demnach eine hohe Wahrscheinlichkeit zum Kauf aufweisen.
Auf das obige Modell übertragen bedeutet das, dass Sie den Anteil derjenigen Nutzer, die in den Suchergebnissen nicht auf Ihre Anzeigen geklickt hat nun auf YouTube erneut ansprechen können. Die Möglichkeit sich mit diesen eigentlich bereits „verlorenen“ Nutzern erneut zu verbinden beschreibt der rote Balken in der Grafik und zeigt das Potential der Custom Intent Audiences auf.

Noch mehr Vorteile: Branding und niedrigere Klickpreise
Durch das Branding dieser Werbestrategie ergibt sich zusätzlich ein langfristiger Effekt auf Ihr Unternehmen. Mehr Menschen kommen mit Ihrem Produkt in Kontakt und Sie erhöhen Ihre Markenbekanntheit. Zusätzlich sind die CPAs (Cost per Conversion) auf YouTube derzeit noch günstiger als bei Search- oder Shopping Kampagnen. Vor allem in Bereichen, bei denen die Klickpreise für Keywords sehr hoch sind, stellen Videos daher meist die günstigere Alternative dar.
Wer also weiß, wie die eigene Zielgruppe nach den eigenen Produkten oder Dienstleistungen sucht, der sollte auf jeden Fall die Möglichkeiten mit YouTube für sich nutzen. Wie Sie erfolgreich auf der Plattform sein können, zeigen wir Ihnen im Beitrag: YouTube-Kanal pushen
Die beste Zeit für Social Media-Beiträge
Daher empfiehlt es sich, die Social Media-User mit neuen Beiträgen gezielt dann ansprechen, wenn sie in ihrem Lieblingsnetzwerk online und besonders aktiv sind. Achtet man auf die bestimmten Zeiten der einzelnen Kanäle, können deutlich mehr Personen erreicht werden, neue Zielgruppen erschlossen und die Interaktionsrate der veröffentlichten Beiträge vergrößert werden. Unsere Social Media-Experten haben sich genauer damit beschäftigt, wann die Zielgruppen über die verschiedenen Social Media-Plattformen am besten erreicht werden können.
Die besten Tage und Uhrzeiten für Facebook-Beiträge

Dank des Newsfeed-Algorithmus erreicht ein Facebook-Beitrag 75 Prozent seiner potenziellen Interaktionen innerhalb der ersten fünf Stunden nach Veröffentlichung. Umso entscheidender ist es daher das Timing, wann ein Beitrag veröffentlicht wird. Auf Facebook ist vor allem die Zielgruppe der 20-29-Jährigen täglich aktiv. Aber auch in der Zielgruppe der 30-49-Jährigen steigt die Zahl täglichen Plattformnutzer stetig. Folglich ist der Großteil der User berufstätig, weshalb die Social Media-Nutzung unter der Woche am Vor- und Nachmittag deutlich eingeschränkt ist. Verschiedene Untersuchungen haben gezeigt, dass die besten Zeiten, um Beiträge unter der Woche auf Facebook zu veröffentlichen, zur Mittagszeit zwischen 12:00-14:00 Uhr und abends nach Feierabend von 18.00-22:00 Uhr ist. Dabei ist die Interaktionsrate am Dienstag nicht ganz so stark und eher ein schlechter Tag, um viel Engagement zu erreichen. Die optimalen Wochentage sind Donnerstag und Freitag. Doch auch am Wochenende sind Facebook-User sehr aktiv. Demnach liegt die beste Zeit am Samstag und Sonntag zwischen 11:00-13:00 Uhr.
Die besten Zeiten für Instagram-Beiträge

Instagram-Beiträge erscheinen nicht mehr streng chronologisch nach Zeitpunkt der Veröffentlichung. Der Content erscheint individuell in Feeds, wenn dieser von der Plattform für die Person als relevant erachtet wird, d.h. wenn er bereits von anderen Personen eine Vielzahl an Likes und Kommentaren erhalten hat. Trotzdem ist es vorteilhaft, Beiträge zu bestimmten Zeiten zu veröffentlichen, um ein möglichst großes Publikum zu erreichen und auch bei anderen Personen weit oben im Feed zu erscheinen. Es werden verschiedene Theorien diskutiert, wann die Instagram-Community besonders aktiv ist. Überwiegend gelten die Zeiten Montag bis Freitag zwischen 12:00-13:00 Uhr und ab 17:00 Uhr als ideal. Hier scheint vor allem Mittwoch 17:00 Uhr der perfekte Zeitpunkt zu sein, um einen Instagram-Beitrag zu veröffentlichen. Eine andere Möglichkeit besteht Beiträge vormittags zwischen 6:00-12:00 Uhr zu posten, da dort weniger Beiträge veröffentlicht werden und die Konkurrenz geringer ist. Entsprechend ist allerdings auch die Anzahl der aktiven User niedriger. Nichtsdestotrotz überprüfen auch in diesem Zeitfenster viele Personen ihren Instagram-Feed, insbesondere vor Arbeitsbeginn. Instagram-Nutzer schauen sich Inhalte über ihr Smartphone an. Daher wird während der Arbeitszeit selten der Feed durchgeschaut. Am Wochenende sollte der Sonntag gemieden werden, um Beiträge zu veröffentlichen. Hier gilt Samstag gegen 17:00 Uhr als bester Zeitpunkt.
Die besten Tage und Uhrzeiten für TikTok-Beiträge

TikTok ist die Social Media-Plattform mit dem aktuell größten Wachstum auf dem deutschen Markt. Hier ist eine sehr junge Zielgruppe aktiv (13-25-Jährige), die überwiegend aus Schülern besteht. Auch wenn die Plattform für viele sehr neu scheint, gibt es auch hierzu Ergebnisse darüber, zu welchen Zeiten man ein Video auf TikTok hochladen sollte. Die besten Zeiten sind vormittags zwischen 6:00-8:00 Uhr, wenn sich die Zielgruppe auf den Weg zur Schule begibt, zwischen 13:00-15:00 Uhr auf dem Nachhauseweg ist und abends zwischen 19:00-23:00 Uhr bevor die User schlafen gehen. Auch hier gilt die Regel wie bei Instagram: Je mehr mit Beiträgen interagiert wird, desto häufiger erscheint dieser Content bei anderen Nutzern im Feed.
Die besten Zeiten für Pinterest-Beiträge

Pinterest ist eine der wenigen Social Media-Plattformen, auf der Beiträge sehr langlebig und nachhaltig sind und Interaktionen entsprechend über einen langen Zeitraum generiert werden. Daher sind die Posting-Zeiten nicht ganz so entscheidend wie bei anderen sozialen Netzwerken. Die Plattform wird sehr aktiv und gerne als Wochenendbegleitung genutzt. Die besten Zeiten für neue Pins liegen am Samstag und Sonntag zur Mittagszeit gegen 12:00-14:00 Uhr und zwischen 19:00-22:00 Uhr. Die Wochentage sind bei Pinterest-Nutzern dagegen weniger beliebt. Hier sollten Beiträge, wenn dann zur Mittagszeit oder deutlich nach Feierabend veröffentlicht werden.
Die besten Zeiten für LinkedIn-Beiträge

Bei den Veröffentlichungszeiten für LinkedIn sind sich Experten überwiegend einig. LinkedIn ist ein berufliches soziales Netzwerk, das in erster Linie von Geschäftsleuten, Vertriebsmitarbeitern und Personalvermittlern verwendet wird. Diese verwenden die Plattform überwiegend während ihrer Arbeitszeit und kontrollieren ihr LinkedIn-Netzwerk im Laufe des Arbeitstages auf neue Informationen und Veränderungen. Beiträge sollten daher am Dienstag, Mittwoch oder Donnerstag zwischen 8:00-12:00 Uhr oder zwischen 16:00-18:00 Uhr veröffentlicht werden. Wochenenden und Feiertage sind dagegen keine guten Zeiten, um viel Sichtbarkeit und Engagement zu erhalten. Warum nicht Montag und Freitag? Am Montag sind viele in Meetings und mit so viel Arbeit eingespannt, dass LinkedIn „zu kurz kommt“. Am Freitag hingegen wollen viele alles möglichst schnell erledigen und dann ab ins Wochenende. Zudem sind Montag und Freitag beliebte Urlaubstage oder werden zum Abbau von Überstunden genutzt. Die LinkedIn-Woche ist also kurz, aber knackig!
Die besten Zeiten für Twitter-Tweets

Pro Sekunde werden weltweit ca. 9.000 Tweets veröffentlicht. Die Lebenszeit eines Tweets ist im Vergleich zu anderen Social Media-Beiträgen daher sehr gering ist. Umso wichtiger ist es, das perfekte Zeitfenster zu finden, in dem die Aufmerksamkeit der Zielgruppe für den Tweet besonders hoch ist. Die besten Zeiten für Beiträge auf Twitter sind vormittags zwischen 6:00-10:00 Uhr, zur Mittagszeit um 12:00 Uhr und nach Feierabend zwischen 16:00-19:00 Uhr. Die besten Tage im B2C-Bereich sind Mittwoch, Samstag und Sonntag und im B2B-Bereich die Wochentage Montag bis Freitag.
Generell gilt
Die verschiedenen Social Media-Kanäle stellen für Unternehmen schon heute enorm wertvolle Kommunikations- und Vertriebskanäle dar – eine Tendenz, die sich täglich verstärkt und durch die Corona-Krise nochmals beschleunigt wurde. Mit vergleichsweise geringem Aufwand können in kürzester Zeit eine Vielzahl an Informationen über das Unternehmen, das Produkt- oder Dienstleitungsportfolio oder anderweitig wichtige News über die sozialen Medien an die relevanten Zielgruppen kommuniziert werden.
Quellen: ARD/ZDF Online-Studie, blog2social.com, hootsuite.com, hubspot.de, wiselytics.com
Was wird am meisten gegoogelt – die Google Trends
Jeder Smartphone Nutzer googelt im Durchschnitt 3,4 Mal am Tag. Während der Corona-Krise sind die Zahlen gestiegen. In Deutschland stieg die durchschnittliche Smartphone-Nutzung am Tag auf 2,3 Stunden, in China sogar auf 5 Stunden. Ein Blick in Google Trends zeigt, wonach Nutzer neuerdings gerne suchen. Der Service von Google stellt die Anzahl eines eingegebenen Suchbegriffs zu einem bestimmten Thema in einer Zeitachse dar. Die Häufigkeit der Eingabe wird außerdem in Relation zum gesamten Suchvolumen gesetzt. So wird das Augenmerk der User ausgedrückt und es können Prognosen zum jeweiligen Thema getroffen werden. Bei uns gibt’s spannende Einblicke, was aktuell online gefragt ist.
Google Trends: Die Devise lautet „selber machen“!
Besonders beliebt ist es, Dinge wieder selbst zu tun. Da beispielsweise die Frisörsalons momentan geschlossen bleiben, stehen viele Kunden vor dem Problem, was sie mit ihrer Haarpracht anfangen sollen. Einige sind geduldig und warten ab, bis die Salons wieder geöffnet haben, um ihren Frisör zu unterstützen. Andere, gerade Männer, die regelmäßig zum Frisör gehen, tun sich dabei eher schwer. Die Google Trends-Abfrage für den Suchbegriff „Haare selbst schneiden“ im unteren Screenshot zeigt, dass es manche wohl nicht mehr bis zur Aufhebung der Ausgangssperre aushalten.
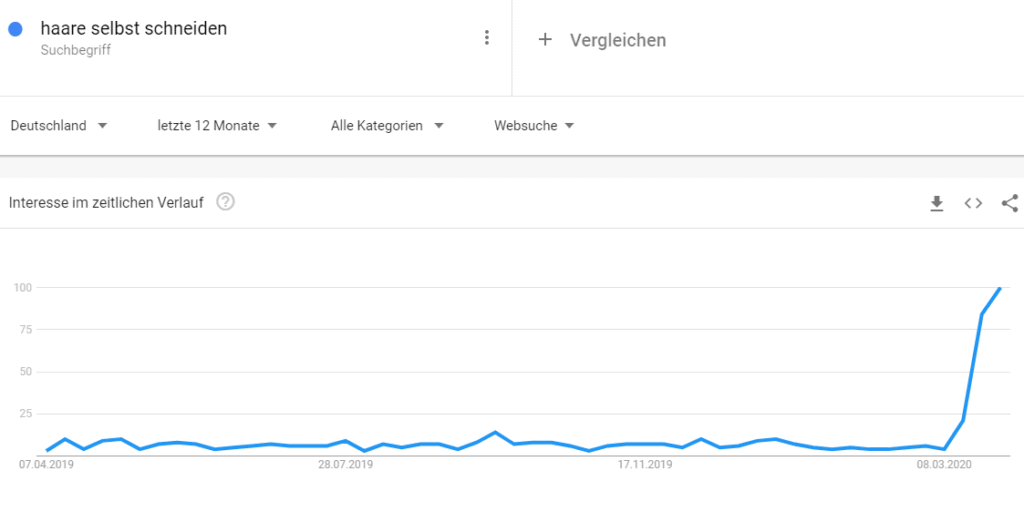
Leere Klopapier-Regale und Klorollen-Memes überfluten die sozialen Netzwerke: Da der ein oder andere sicher selbst schon vor dem leeren Supermarkt-Regal stand, werden die Leute erfinderisch. Wie man Toilettenpapier selbst macht, wollten bereits Ende September 2019 einige Leute von Google wissen. Die Halloween-Scherze mit selbstgemachtem Klopapier sind im März 2020 jedoch nicht der Grund für den Anstieg der Suchanfragen. Auch „Alternative zu Klopapier“ wird nun öfter gesucht als sonst. Der sprunghafte Anstieg der Popularität von „Bidet“ stellt beide Klopapieralternativen in den Schatten. Vielleicht wird das französische Sitzwaschbecken ja das neue Lieblingsteil der Deutschen?
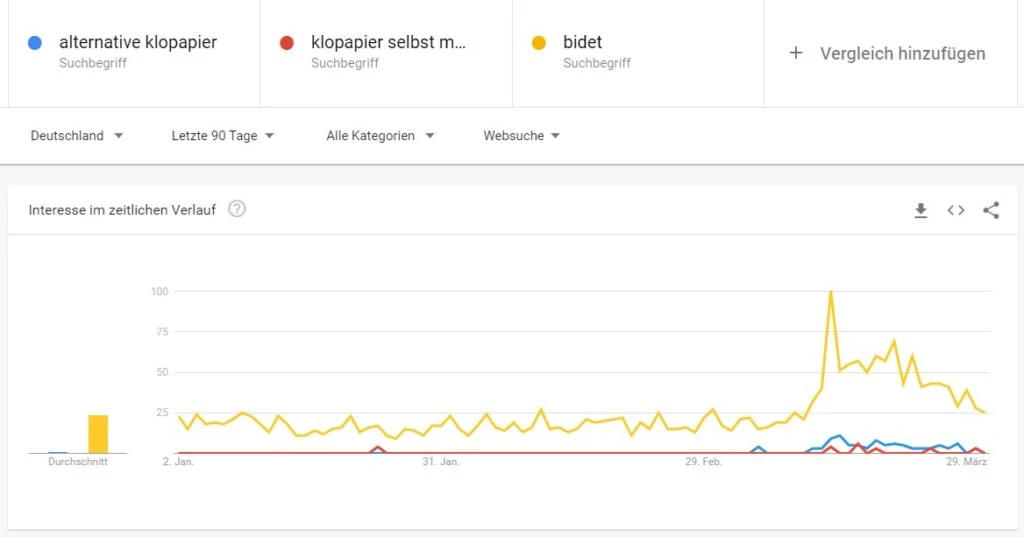
Auch Hausarbeiten sind bei den Anfragen vorne mit dabei
Beschäftigungsmöglichkeiten werden gerne gesucht: Eine weitere Analyse in Google Trends hat ergeben, dass der Suchbegriff „Fenster putzen“ seit Anfang März ziemlich an Anfragen gewonnen hat. Viele, die jetzt zu Hause sind, versuchen wohl die Zeit mit nützlichen Dingen totzuschlagen. Die Suchanfragen zeigen: Nicht jeder weiß, wie Fenster putzen geht – ob das wohl an den sprichwörtlichen zwei linken Händen der Bürohengste und Home-Office-Helden liegt?
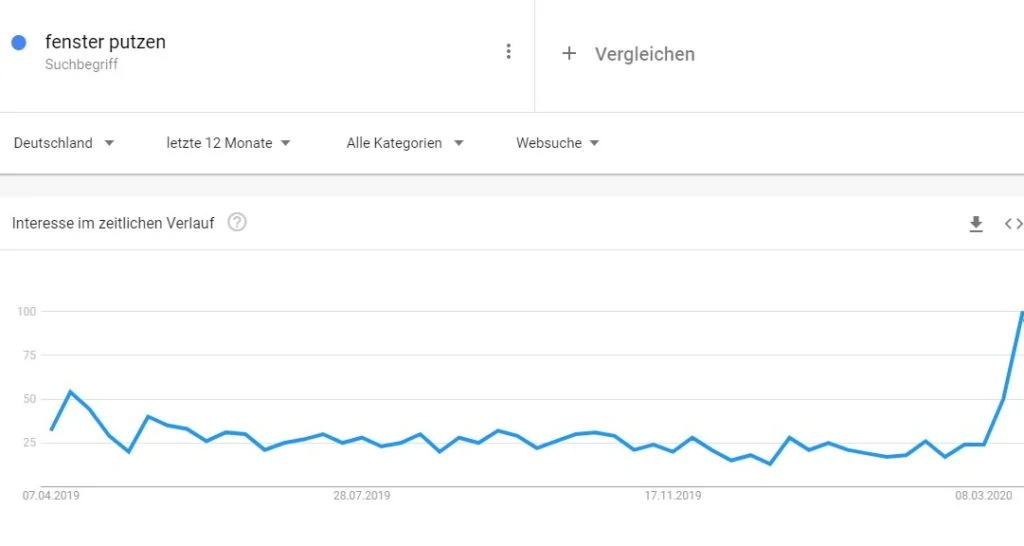
Was ist jetzt wichtig? In Verbindung bleiben
Video-Chat-Dienste oder Plattformen für Videokonferenzen sind derzeit gefragter denn je: Viele Nutzer scheinen ihren alten Skype-Account zu reaktivieren. Einige nutzen Zoom für Videokonferenzen, während Microsoft Teams oder Slack nur einen schwachen Anstieg zu verzeichnen haben.
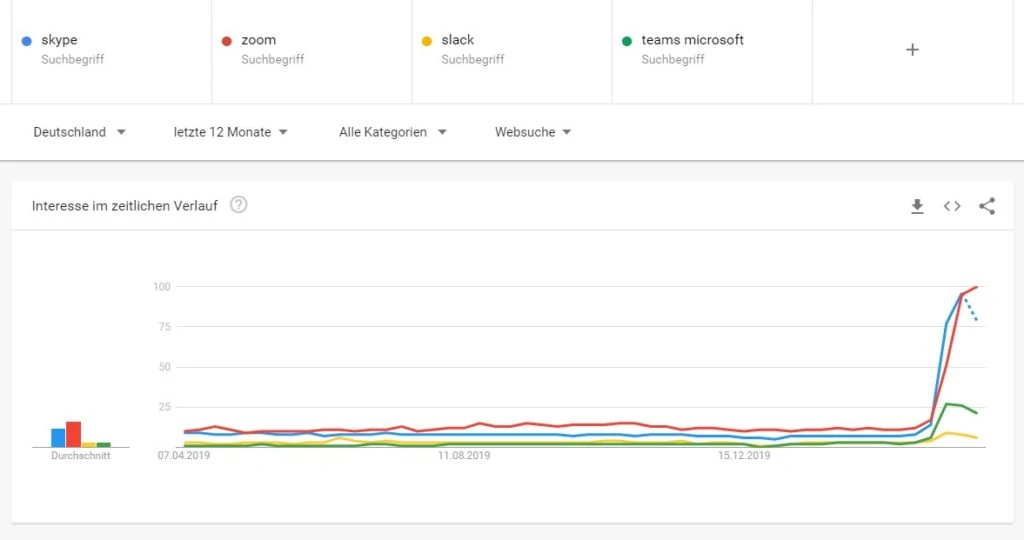
Puzzle: das Synonym für lange Stunden zu Hause
Puzzeln gehört nach wie vor zu den Klassikern, um viel Zeit in den eigenen vier Wänden zu verbringen. Die Mehr-Zeit bringt User auch dazu, Ihre eigenen Ziele höher zu stecken: So werden statt 500-Teile-Puzzles jetzt gerne 1000-Teile-Puzzles gesucht. Die 5000-Teile-Puzzles sind für einige dann wohl doch wieder eine Nummer zu groß. Motiviert für mehr! Die Suchanfragen zu Puzzles zeigen außerdem: Obwohl oder gerade weil viele Deutsche nun Zeit zu Hause verbringen, suchen Sie im Internet nach Zeitvertreib, nach Produkten und Dienstleistungen.
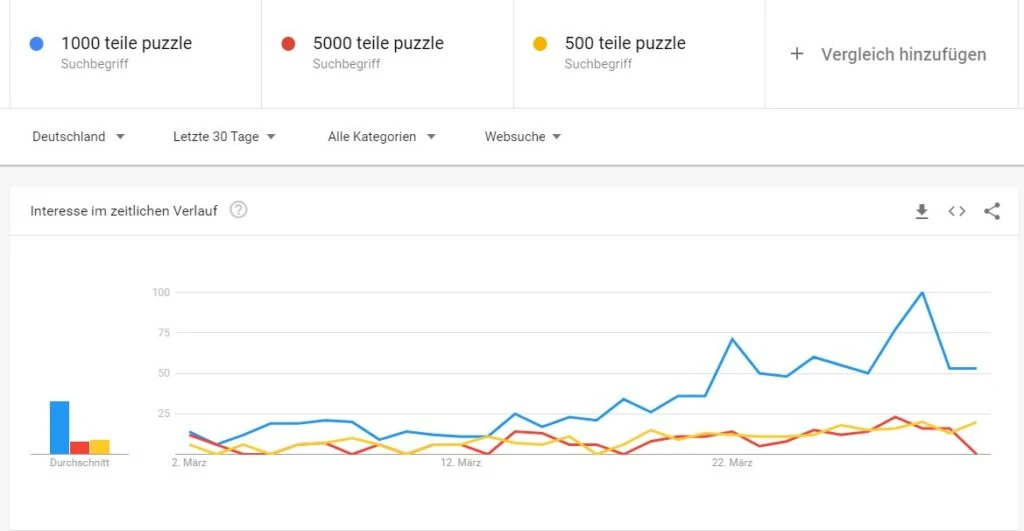
Kunden trotz Ausgangssperre erreichen? Suchmaschinenwerbung hilft!
Ob Zeitvertreib oder Notwendiges: Viele Menschen suchen nun via Google, was Sie nicht in Kaufhäusern finden. Suchmaschinenwerbung (SEA) nutzt dieses neue Online-Potential, denn die Kampagnen lassen sich schnell erstellen und flexibel auf den aktuellen Bedarf der Kunden zuschneiden. Anzeigen in den Suchergebnissen von Google werden dabei nur ausgespielt, wenn Nutzer tatsächlich nach dem entsprechenden Keyword suchen. So sehen nur Kunden die Anzeigen, die auf der Suche nach Produkten oder Dienstleistungen sind.
Denken Sie daran: Nicht nur Krisengewinner profitieren von der aktuellen Lage. Gerade jetzt zeigen sich Anreize und Chancen für Unternehmen, die keine Reinigungsmittel oder Hygieneartikel im Sortiment haben. Sprechen Sie mit uns über die Möglichkeiten gezielter Online-Werbung.
Sie haben Fragen oder wollen mehr Social-Media-Marketing betreiben? Unser kompetentes Team berät Sie gerne.