
Was versteht man unter Duplicate Content?
Duplicate Content ist gleicher oder nahezu gleicher Inhalt auf unterschiedlichen Seiten. Dabei wird zwischen externem und internem DC unterschieden. Externer Duplicate Content liegt vor, wenn es sich um mehrere Domains handelt, interner DC, wenn die Inhalte innerhalb einer Domain dupliziert werden. Doch nicht jeder Duplicate Content entsteht aus Absicht. Deshalb unterscheidet Google zwischen böswillig und nicht böswillig dupliziertem Inhalt. Absichtlich erstellter Duplicate Content entsteht, um schnell Klicks und Traffic zu generieren, ohne die nötige Arbeit in den Text zu stecken. Oft wird einfach bei der Konkurrenz geklaut. Nicht böswillig duplizierter Inhalt kommt dagegen häufig vor, ohne dass der Betreiber der Website es überhaupt merkt. Zum Beispiel nämlich dann, wenn es verschiedene Versionen einer Website gibt (Desktopversion, mobile Version, Druckversion).
Erkennt die Suchmaschine Duplicate Content als betrügerische Maßnahme, kann das für das Ranking der jeweiligen Website ernsthafte Konsequenzen haben. Denn Google selbst kommuniziert in einem Artikel zur Vermeidung von Duplicate Content klar, dass die Suchmaschine DC nicht duldet, wenn dieser erstellt wurde, um Suchergebnisse zu manipulieren. In schlimmen Fällen von duplizierten Inhalten kann es dazu kommen, dass die betroffenen Seiten Ranking einbüßen. Der Grund: Nutzerfreundlichkeit. Wenn der gleiche Inhalt auf verschiedenen Seiten zu sehen ist und diese bei der jeweiligen Suchanfrage nacheinander aufgelistet werden, sieht der User immer nur den gleichen Content, ohne einen Mehrwert an Informationen zu erhalten.
Wie lässt sich Duplicate Content vermeiden?
Um Duplicate Content zu vermeiden, ist es wichtig, sich darüber bewusst zu werden, wo DC überall vorkommen kann. Duplizierter Content wird häufig generiert durch:
- automatisch erzeugte Websites
- identische Internetseiten, die über verschiedene URLs zugänglich sind
- verschiedene Versionen einer Seite wie bsp. die Druckversion
- sich kaum voneinander unterscheidende Unterseiten zu einem Thema oder einem Produkt, z. B. Produktdetailseiten
Unique Content generieren
Damit Duplicate Content gar nicht erst entsteht, benötigt man möglichst viel "Unique Content", der nur auf der jeweiligen Website zu finden ist. Das bedeutet nicht, dass man nicht die gleichen Informationen wie andere Seiten haben darf, sondern lediglich, dass man übernommenes Wissen als solches kennzeichnet und dieses so umschreibt, dass es in dieser Form nur auf der eigenen Website zu finden ist.
Duplizierte URLs vermeiden
Die oberste Regel, um DC zu vermeiden, lautet: Jede Landing Page ist nur durch eine unique URL (die perfekte SEO-URL) erreichbar. Bei unterschiedlichen URLs, die alle zu einer Seite führen oder auch bei mehreren Versionen einer Website sucht sich Google nämlich eine URL als kanonisch aus, welche dann die Haupt-URL ist. Diese wird von der Suchmaschine dann gecrawlt, wohingegen die anderen URLs kaum noch relevant sind. Deshalb sollte man lieber von Anfang an selbst festlegen, welche URL kanonisch sein soll.
Nützliche Maßnahmen gegen Duplicate Content
Außerdem ist es wichtig,
- auf Einheitlichkeit zu achten, indem man nicht auf interne Linkvariationen zurückgreift, sondern immer die gleichen Links nutzt.
- Top-Level-Domains für landesspezifischen Content zu gebrauchen; bsp. ".de" statt ".com" für Deutschland.
- möglichst keine "Platzhalter" zu veröffentlichen, also Seiten, die noch keinen richtigen Content haben.
- ähnliche Inhalte und sich wiederholende Textbausteine ganz zu vermeiden oder zu reduzieren: Bei vielen Seiten mit ähnlichen Inhalten empfiehlt es sich, diese entweder zu einer einzelnen Seite zusammenzuführen oder so weit auszubauen, dass die Unterschiede deutlich werden und sich der Content nicht mehr überschneidet.
- bei gleichem Inhalt auf verschiedenen Websites die Originalseite festzulegen und mit der 301-Weiterleitung darauf zu leiten. Hier hilft ein Blick in die Google Search Console, um die Seite festzulegen, die Google als relevanter ansieht.
Content auf Duplikate überprüfen
Auf Nummer sicher gehen und den eigenen Content überprüfen? Das geht ganz einfach mit verschiedenen Tools:
Mit der "Google Search Console" kann man schnell & unkompliziert Duplicate Content ausfindig machen. Dafür geht man einfach auf den Reiter "Index", dann auf "Abdeckungen" und wählt im Diagramm den Filter "Ausgeschlossen". Innerhalb der Tabelle kann man sich dann etwaige Duplikate anzeigen lassen, ebenso wie die dazugehörigen URLs. Ist hier eine URL aufgelistet, die eigentlich für ein bestimmtes Keyword-Set ranken soll? Dann lohnt sich die Überprüfung der als Original angenommenen Landing Page.
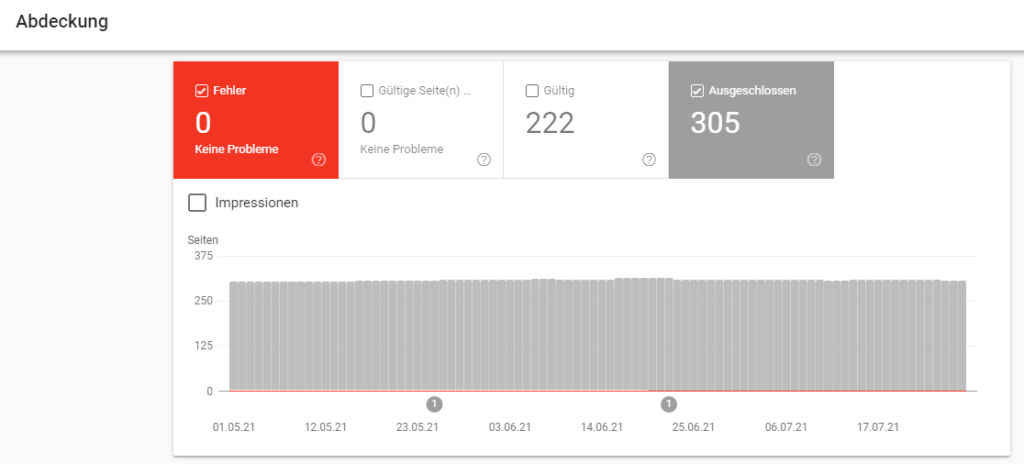
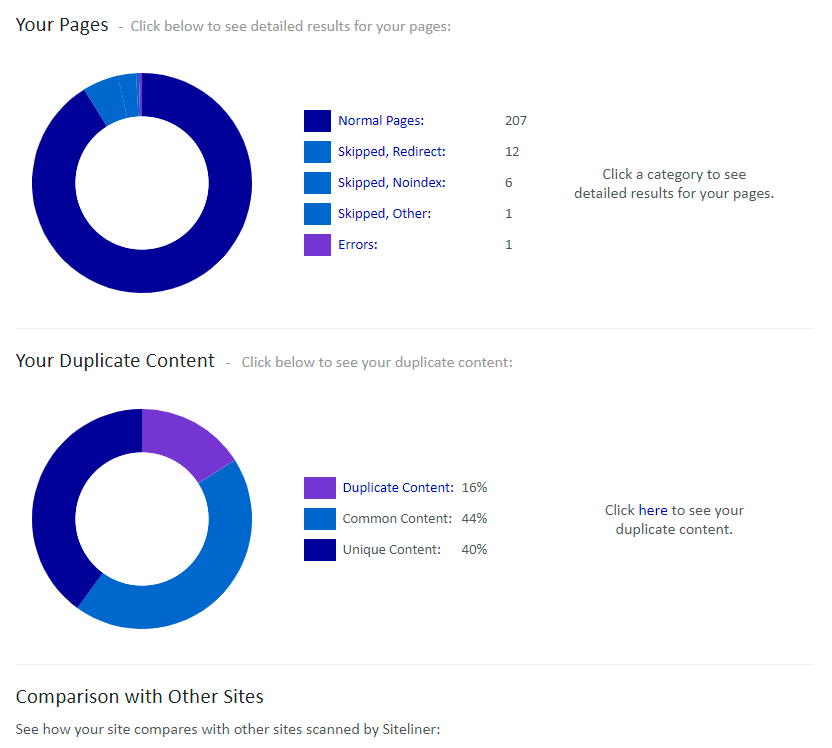
Eine weitere Möglichkeit zur Content-Überprüfung ist das Tool "Siteliner". Die Anwendung überprüft die gesamte Domain und gibt einen Report zu möglichem Duplicate Content aus. Die kritischen Seiten können dann einzeln angesehen und überprüft werden. Das Tool färbt kritische Textteile ein und zeigt die URLs, die denselben Inhalt tragen - sowohl auf der eigenen wie auch auf fremden Domains.
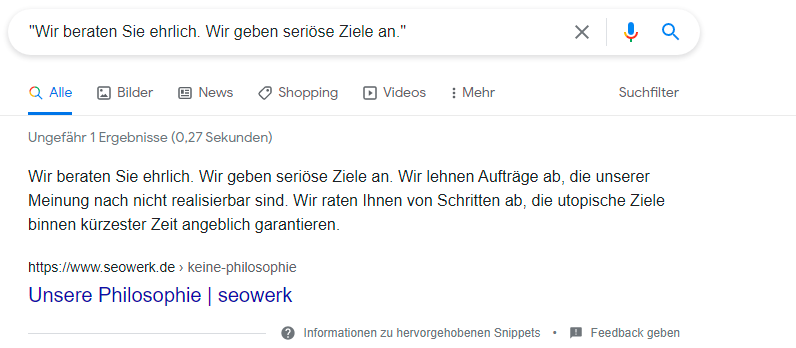
Alternativ dazu kann man Inhalte auch manuell prüfen, indem man einzelne Phrasen und Textbausteine googelt. Optimalerweise erscheint dann nur die eigene Seite. Wenn der jeweilige Textbaustein noch auf anderen Seiten zu finden ist, sollten diese genau unter die Lupe genommen werden:
Darüber hinaus gibt es zur Überprüfung von Duplicate Content noch zahlreiche weitere Tools, die teilweise kostenpflichtig sind.
Schutz vor DC durch andere Websites
Duplicate Content entsteht aber nicht nur durch eigenes Verschulden. Andere Domains bedienen sich häufig an guten Inhalten, indem sie diese einfach kopieren. Manchmal ranken dann die Websites, die den Inhalt von anderen geklaut haben, sogar höher als die originalen. Um seinen Unique Content auch als solchen zu erhalten, sollte man seine Inhalte also regelmäßig überprüfen oder den Alarm mancher Tools nutzen, der einen bei gleichem oder stark ähnelndem Content benachrichtigt. Des Weiteren ist es wichtig, von Anfang an kanonische URLs zu setzen und somit die eigene Seite als Original festzulegen.
Fazit zu Duplicate Content
Was auf den ersten Blick nach viel Aufwand aussieht, ist eigentlich gar nicht so kompliziert. Wir halten fest:
Duplicate Content kann das Ranking der eigenen Seite negativ beeinflussen. Setzt man sich jedoch früh mit dem Thema DC auseinander, kann man sich vor fremden Übergriffen schützen und die eigene Seite unique halten. Wir empfehlen die regelmäßige Prüfung auf duplizierte Inhalte sowie den sinnvollen Einsatz von kanonischen URLs.
Bei weiteren Fragen zu Duplicate Content sowie zu anderen Themen aus den Bereichen Suchmaschinenoptimierung oder SEO-Content steht das seowerk-Team gerne mit einer persönlichen Beratung zur Verfügung.
